基于分数的生成模型
基于能量的模型
任意分布都可以被写为:
pθ(x)=Zθ1e−fθ(x)(152)
fθ(x) 是一个任意的、参数化的函数——能量函数,通常被建模为一个NN,Zθ 是正则化常数使得 ∫pθ(x)dx=1 ,如果使用最大似然估计,对复杂的 fθ(x) 来说,Zθ 可能难以处理
分数模型
上面的问题可以使用一个NN sθ(x) 来学习 p(x) 的分数函数 ∇logp(x) 所避免。动机:
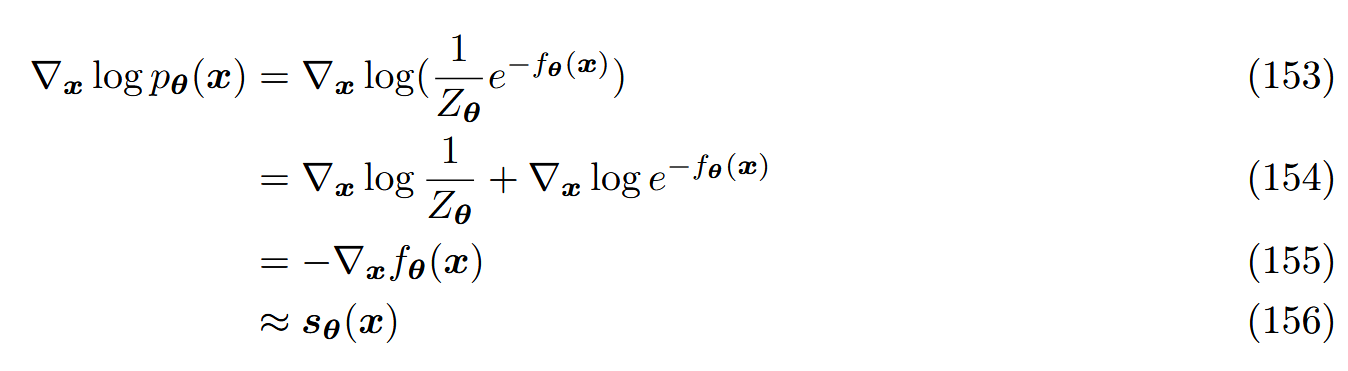
因此不需要表示任何正则化常数,分数模型可以通过最小化Fisher散度来优化:
Ep(x)[∥sθ(x)−∇logp(x)∥22](157)
对于每个 x 来说,它的对数似然的梯度根本上描述了在数据空间中进一步增加它的对数似然的方向。直觉上,分数函数在数据 x 所在的整个空间上定义了一个向量场,指向众数:
通过学习真实数据分布的分数函数,我们可以从相同空间中的任一点开始,逐渐地跟随分数直到模式到达来生成样本。采样过程为已知的郎之万采样:
xi+1←xi+c∇logp(xi)+2cϵ, i=0,1,...,K(158)
x0 是从先验分布中随机采样,ϵ∼N(ϵ;0,I) 是一个额外的噪声项用来保证生成样本不总是崩溃到一个模式,而是为了多样性环绕在它周围,保留一定的随机性。由于ground-truth分数函数对于复杂分布的自然图像来说不可获取,于是使用分数匹配方法来解决。
普通分数匹配存在三个问题:
-
当 x 在高维空间的低维流形上时,分数函数是不明确的。所有不在低维流形的点的概率为0,此时对数没有定义,而自然图像通常在整个环境空间的低维流形上
-
通过普通分数匹配训练的分数函数在低密度区域可能是不正确的,因为我们最小化的目标是关于 p(x) 的期望,从它的样本中训练,模型无法接收到很少见或者看不到的样本的正确的学习信号。(采样策略是高维空间的随机位置开始,很可能是随机噪声)
-
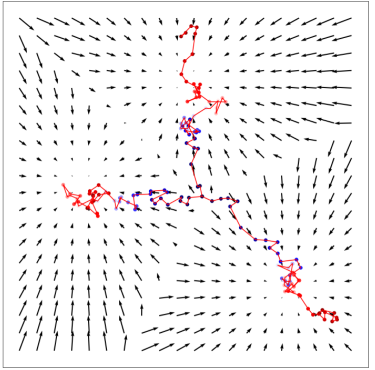
郎之万动力采样可能不会拟合,即使使用ground-truth分数:
假设真实数据分布是两个不相交的分布的混合
p(x)=c1p1(x)+c2p2(x)(159)
在计算分数时,它们的混合系数被丢掉,那么从它们中间的初始点使用郎之万动力学采样的话,到达它们每个模式的机会都是粗略相等的,尽管可能某一个分布的权重更大
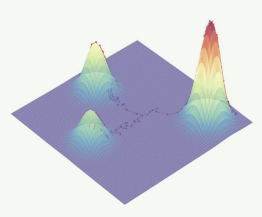
解决方案:在数据中加入多个水平的高斯噪声(去噪分数匹配)
- 由于高斯噪声的假设是整个空间,于是扰动后的数据不再局限于低维流形
- 加入较大的高斯噪声将增大每种模式在数据分布中覆盖的面积,在低密度区域增加了更多训练信号
- 加入多个水平的高斯噪声并增加方差将使得结果的中间分布尊重ground-truth的混合系数
于是,形式上,选择正的噪声水平序列 {σt}t=1T ,以及定义一个逐渐扰动数据分布的序列:
pσt(xt)=∫p(x)N(xt;x,σt2I)dx(160)
sθ(x,t) 使用分数匹配训练学习同时所有噪声水平的分数函数:
θarg mint=1∑Tλ(t)Epσt(xt)[∥sθ(x,t)−∇logpσt(xt)∥22](161)
λ(t) 是正的权重函数,通常被选择为 λ(i)=σi2 由于噪声水平随着时间稳定下降,因此要随着时间减少步长,使得样本最后集中在真实的模式上。
∇xtlogpσt(xt)=∇xtlogpσt(xt∣x)p(x)=∇xtlogpσt(xt∣x)(162)
∇xtlogpσt(xt∣x)=∇xtlog{2πσt1exp(−2σt2(xt−x)2)}=∇xt[−2σt2(xt−x)2]=−σt2xt−x=−σtϵ(163)
于是优化目标可以写为:
θarg mint=1∑Tλ(t)Epσt(xt)[sθ(x,t)+σt2xt−x22]=θarg mint=1∑TEpσt(xt)[∥σtsθ(x,t)+ϵ∥22](164)
SDE推导
众所周知,扩散模型中 x0→xT,xT→x0 的过程一种随机过程,于是考虑使用随机微分方程(Stochastic Differential Equations,SDE)来刻画。
原始扩散过程为离散形式,使用SDE进行连续的描述,于是前向扩散过程可以看作一个伊藤扩散过程的解:
dx=f(x,t)dx+g(t)dω
其中:
dx=Δt→0lim(xt+Δt−xt)
因此原来离散形式的 xt→xt+1 就变为连续形式的 xt→xt+Δt ,于是:
xt+Δt=xt+确定部分f(x,t)Δt+随机部分g(t)Δtϵ,ϵ∼N(0,I)
原来离散的前向过程:x0→x1→x2→...→xT ,现在连续的前向过程:x0→xΔt→x2Δt→...→xT
有了前向过程的SDE后,需要分析反向过程以还原真实分布,
p(xt+Δt∣xt)=N(xt+Δt;xt+f(x,t)Δt,g2(t)ΔtI)∝exp(2g2(t)Δt∥xt+Δt−xt−f(x,t)Δt∥2)
根据贝叶斯规则:
p(xt∣xt+Δt)=p(xt+Δt)p(xt+Δt∣xt)p(xt)=p(xt+Δt∣xt)exp(logp(xt)−logp(xt+Δt))=exp(−2g2(t)Δt∥xt+Δt−xt−f(x,t)Δt∥2+logp(xt)−logp(xt+Δt))
对 logp(xt+Δt) 进行泰勒展开:
logp(xt+Δt)≈logp(xt)+(xt+Δt−xt)∇xtlogp(xt)+Δt∂t∂logp(xt)
代入得:
p(xt∣xt+Δt)∝exp(−2g2(t)Δt∥xt+Δt−xt−f(x,t)Δt∥2+(xt+Δt−xt)∇xtlogp(xt)−Δt∂t∂logp(xt))=exp(−2g2(t)Δtxt+Δt−xt−[f(x,t)−g2(t)∇xtlogp(xt)]Δt2+Ot)
当 Δt→0 时,Ot→0 ,于是:
p(xt∣xt+Δt)∝exp(−2g2(t)Δtxt+Δt−xt−[f(x,t)−g2(t)∇xtlogp(xt)]Δt2)≈exp(−2g2(t+Δt)Δtxt−xt+Δt+[f(x,t+Δt)−g2(t+Δt)∇xt+Δtlogp(xt+Δt)]Δt2)
因此:
p(xt∣xt+Δt)=N(xt;xt+Δt−[f(x,t+Δt)−g2(t+Δt)∇xt+Δtlogp(xt+Δt)]Δt,g2(t+Δt)ΔtI)
取 Δt→0 ,以及 dx=Δt→0lim(xt+Δt−xt) 得最后的reverse-time SDE:
dx=[f(x,t)−g2(t)∇xlogpt(x)]dt+g(t)dω

VE-SDE vs. VP-SDE
将NCSN以及DDPM均考虑到SDE框架中,分别为Variance Exploding(VE) SDE和Variance Preserving(VP) SDE。
VE-SDE
对于NCSN,扩散公式为:
xT=x0+σTε
依靠非常大的 σT 使得 xT 变为以 ϵ 主导的高斯噪声,因此是Variance Exploding(方差爆炸)。
NCSN每一步的扰动核 pσi(x∣x0) 的马尔科夫链表示:
xi=xi−1+σi2−σi−12zi−1,i=1,...,N
这里的 zi−1∼N(0,I) ,当 N→∞ 时,马尔科夫链 {xi}i=1N 就变成了连续的随机过程 {x(t)}t=01 ,{σi}i=1N 变为函数 σ(t) , zi 变为 z(t) , 这里的连续时间变量 t∈[0,1] , 而不是整数 i∈{1,2,...,N}. 令 x(Ni)=xi,σ(Ni)=σi,z(Ni)=zi , 于是 Δt=N1,t∈{0,N1,...,NN−1} :
x(t+Δt)=x(t)+σ2(t+Δt)−σ2(t)z(t)=x(t+Δtσ2(t+Δt)2−σ2(t)Δtz(t)=x(t)+ΔtΔσ2Δtz(t)
于是当 Δt→0 时:
f(x,t)=0,g(t)=dtd(σt2)
于是VE-SDE为:
dx=dtd(σt2)dω
VP-SDE
对于DDPM,扩散公式为:
xT=αˉTx0+1−αˉTε
依靠非常小的 αˉT 去压制 x0 ,而本身方差 1−αˉT 并不大,因此是Variance Preserving(方差缩紧)。
DDPM的扰动核 {pαi(x∣x0)}i=1N , 它的离散化的马尔科夫链表示:
xi=1−βixi−1+βizi−1,i=1,2,...,N
这里 zi−1∼N(0,I) , 为了获得当 n→∞ 时的马尔科夫链的极限,定义一个噪声的辅助集合 {βˉi=Nβi}i=1N ,于是:
xi=1−Nβˉixi−1+Nβˉizi−1,i=1,2,...,N
当 N→∞ 时,同上,得:
x(t+Δt)=1−β(t+Δt)Δt x(t)+β(t+Δt)Δt z(t)≈(1−21β(t+Δt)Δt)x(t)+β(t+Δt)Δt z(t)≈(1−21β(t)Δt)x(t)+β(t)Δt z(t)
于是当 Δt→0 时:
f(x,t)=−21β(t)x(t),g(t)=β(t)
于是VP-SDE为:
dx=−21β(t)xdt+β(t)dω