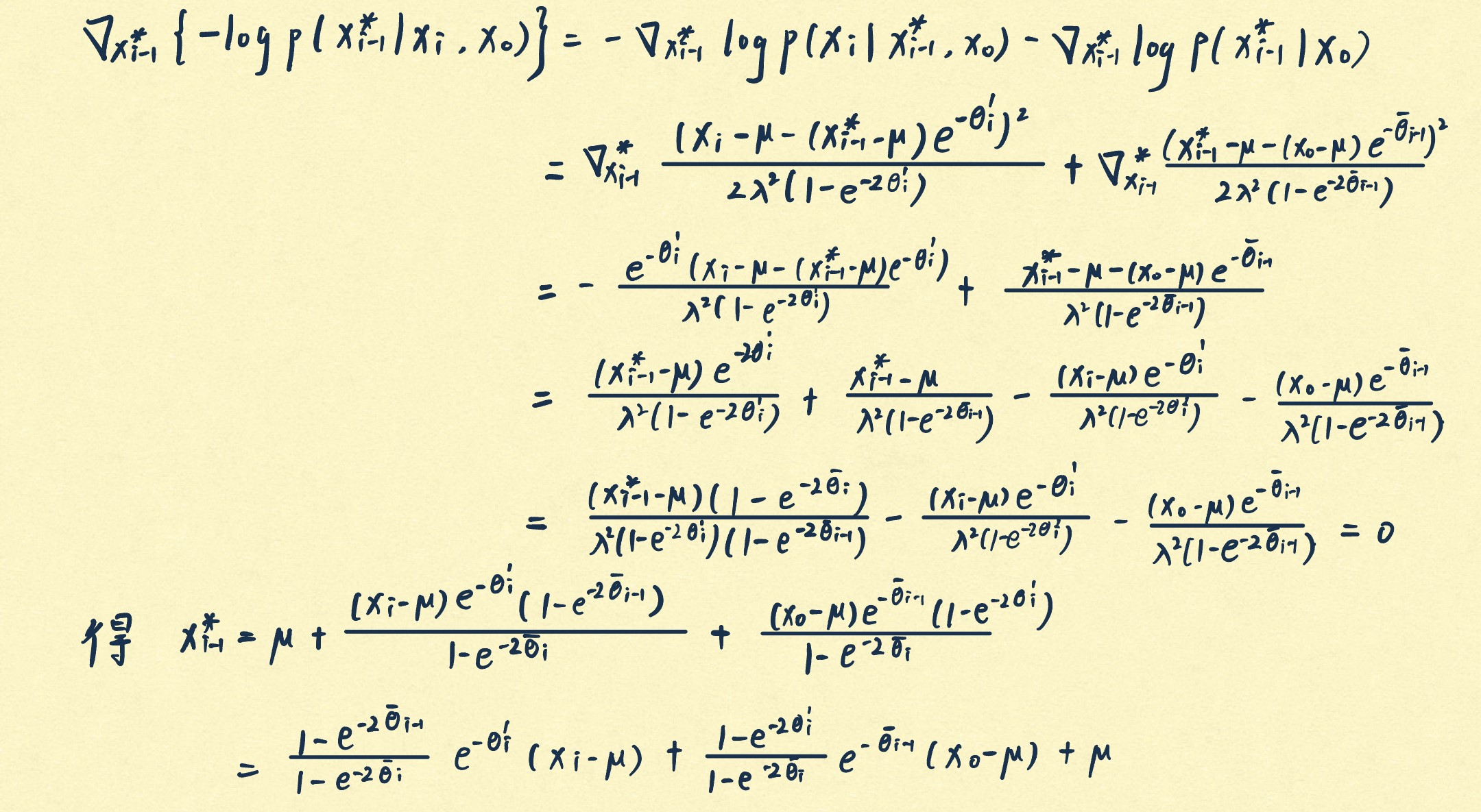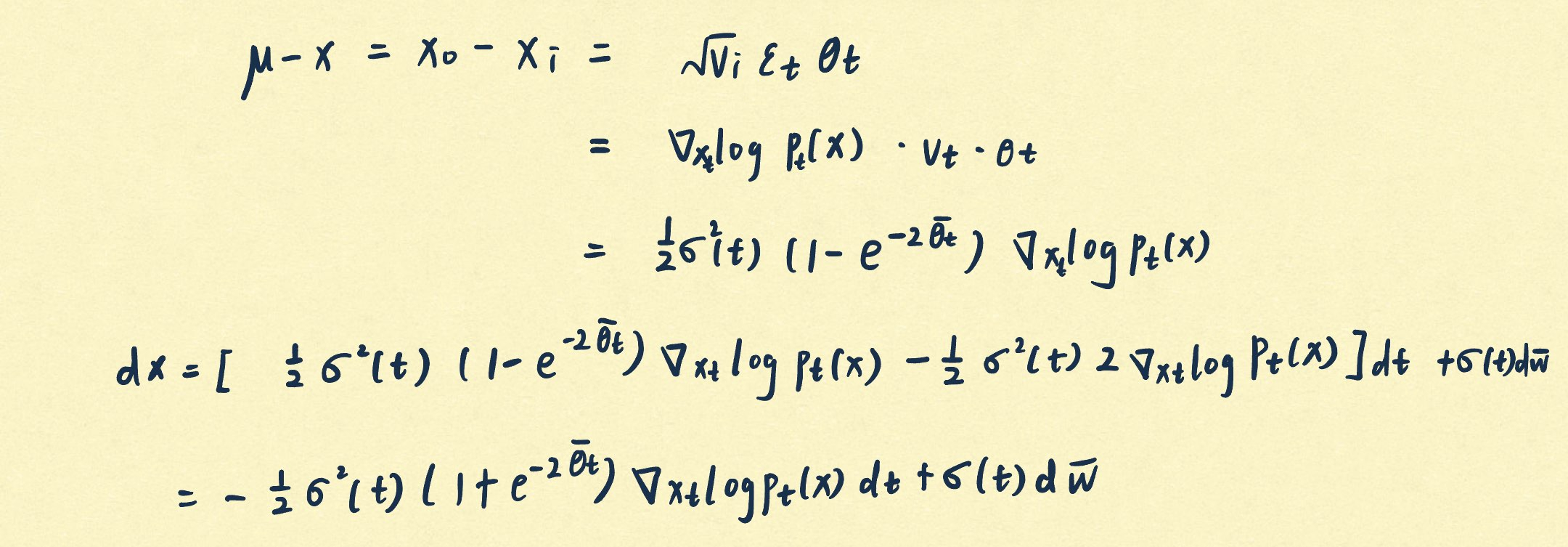Image Restoration with Mean-Reverting Stochastic Differential Equations
背景
以往的方法的反向过程会初始化一个较高方差的噪声,可能会导致ground-truth高质量图像的恢复效果不好,虽然可以获得较高的感知分数,但是往往会在基于像素或结构的退化标准方面表现不太满意。
贡献
为一般的IR问题提出一种SDE方法。mean-recerting SDE关键思想:将高质量的图像转换为退化图像,作为具有固定高斯噪声的均值状态 ,然后去估计reverse-time SDE,不需要有任何task-specific的先验知识。提出了最大似然目标学习优化的reverse轨迹。
方法
前向过程
d x = θ t ( μ − x ) d t + σ t d w dx=\theta_t(\mu-x)dt+\sigma_tdw
d x = θ t ( μ − x ) d t + σ t d w
μ \mu μ θ t , σ t \theta_t,\sigma_t θ t , σ t μ \mu μ x ( 0 ) x(0) x ( 0 ) μ \mu μ x ( 0 ) x(0) x ( 0 ) x ( 0 ) x(0) x ( 0 ) σ t 2 / θ t = 2 λ 2 \sigma_t^2/\theta_t=2\lambda^2 σ t 2 / θ t = 2 λ 2 λ 2 \lambda^2 λ 2 x ( s ) , s < t x(s),s<t x ( s ) , s < t
x ( t ) = μ + ( x ( s ) − μ ) e − θ ˉ s : t + ∫ s t σ z e − θ ˉ z : t d w ( z ) x(t)=\mu+(x(s)-\mu)e^{-\bar\theta_{s:t}}+\int_s^t\sigma_ze^{-\bar\theta_{z:t}}dw(z)
x ( t ) = μ + ( x ( s ) − μ ) e − θ ˉ s : t + ∫ s t σ z e − θ ˉ z : t d w ( z )
θ ˉ s : t : = ∫ s t θ z d z \bar\theta_{s:t}:=\int_s^t\theta_zdz θ ˉ s : t := ∫ s t θ z d z p ( x ( t ) ∣ x ( s ) ) = N ( x ( t ) ∣ m s : t ( x ( s ) ) , v s : t ) p(x(t)|x(s))=\mathcal N(x(t)|m_{s:t}(x(s)),v_{s:t}) p ( x ( t ) ∣ x ( s )) = N ( x ( t ) ∣ m s : t ( x ( s )) , v s : t )
m s : t ( x ( s ) ) : = μ + ( x ( s ) − μ ) e − θ ˉ s : t , v s : t : = ∫ s t σ z 2 e − 2 θ ˉ z : t d z = λ 2 ( 1 − e − 2 θ ˉ s : t ) m_{s:t}(x(s)):=\mu+(x(s)-\mu)e^{-\bar\theta_{s:t}},\\
v_{s:t}:=\int_s^t\sigma_z^2e^{-2\bar\theta_{z:t}}dz\\
=\lambda^2(1-e^{-2\bar\theta_{s:t}})
m s : t ( x ( s )) := μ + ( x ( s ) − μ ) e − θ ˉ s : t , v s : t := ∫ s t σ z 2 e − 2 θ ˉ z : t d z = λ 2 ( 1 − e − 2 θ ˉ s : t )
证明:
需求解的SDE:
d x = θ t ( μ − x ) d t + σ t d w \mathrm dx=\theta_t(\mu-x)\mathrm dt+\sigma_t \mathrm dw
d x = θ t ( μ − x ) d t + σ t d w
为简便,使用 θ ˉ t \bar\theta_t θ ˉ t θ ˉ 0 : t \bar\theta_{0:t} θ ˉ 0 : t
ψ ( x , t ) = x e θ ˉ t \psi(x,t)=x\mathrm e^{\bar\theta_t}
ψ ( x , t ) = x e θ ˉ t
根据伊藤公式:
d ψ ( x , t ) = ∂ ψ ∂ t ( x , t ) d t + ∂ ψ ∂ x ( x , t ) f ( x , t ) d t + 1 2 ∂ 2 ψ ∂ x 2 ( x , t ) g ( t ) 2 d t + ∂ ψ ∂ x ( x , t ) g ( t ) d w t \mathrm d\psi(x,t)=\frac{\partial\psi}{\partial t}(x,t)\mathrm dt+\frac{\partial\psi}{\partial x}(x,t)\mathbf f(x,t)\mathrm dt\\
+\frac12\frac{\partial^2\psi}{\partial x^2}(x,t)g(t)^2\mathrm dt\\
+\frac{\partial\psi}{\partial x}(x,t)g(t)\mathrm {dw_t}
d ψ ( x , t ) = ∂ t ∂ ψ ( x , t ) d t + ∂ x ∂ ψ ( x , t ) f ( x , t ) d t + 2 1 ∂ x 2 ∂ 2 ψ ( x , t ) g ( t ) 2 d t + ∂ x ∂ ψ ( x , t ) g ( t ) d w t
将式 ( 4 ) (4) ( 4 ) ( 6 ) (6) ( 6 )
d ψ ( x , t ) = μ θ t e θ ˉ t d t + σ t e θ ˉ t d w t \mathrm d\psi(x,t)=\mu\theta_t\mathrm e^{\bar\theta_t}\mathrm dt+\sigma_t\mathrm e^{\bar\theta_t}\mathrm{dw}_t
d ψ ( x , t ) = μ θ t e θ ˉ t d t + σ t e θ ˉ t dw t
积分得:
ψ ( x , t ) − ψ ( x , s ) = ∫ s t μ θ z e θ ˉ z d z + ∫ s t σ z e θ ˉ z d w ( z ) \psi(x,t)-\psi(x,s)=\int_s^t\mu\theta_z\mathrm e^{\bar\theta_z}\mathrm dz+\int_s^t\sigma_z\mathrm e^{\bar\theta_z}\mathrm{dw}(z)
ψ ( x , t ) − ψ ( x , s ) = ∫ s t μ θ z e θ ˉ z d z + ∫ s t σ z e θ ˉ z dw ( z )
在这里,∫ s t σ z e θ ˉ z d w ( z ) ∼ N ( 0 , ∫ s t σ z 2 e 2 θ ˉ z d z ) \int_s^t\sigma_z\mathrm e^{\bar\theta_z}\mathrm{dw}(z)\sim\mathcal N(0,\int_s^t\sigma^2_z\mathrm e^{2\bar\theta_z}dz) ∫ s t σ z e θ ˉ z dw ( z ) ∼ N ( 0 , ∫ s t σ z 2 e 2 θ ˉ z d z )
证明:
V a r ( ∫ s t H z d W ( z ) ) ≈ V a r ( ∑ i = 1 N H t i ( W t i − W t i − 1 ) ) = ∑ i = 1 N V a r ( H t i ( W t i − W t i − 1 ) ) = ∑ i = 1 N H t i 2 V a r ( W t i − W t i − 1 ) = ∑ i = 1 N H t i 2 ( t i − t i − 1 ) Var(\int_s^tH_zdW(z))\approx Var(\sum_{i=1}^NH_{t_i}(W_{t_i}-W_{t_{i-1}}))\\
=\sum_{i=1}^NVar(H_{t_i}(W_{t_i}-W_{t_{i-1}}))\\
=\sum_{i=1}^NH_{t_i}^2Var(W_{t_i}-W_{t_{i-1}})\\
=\sum_{i=1}^NH_{t_i}^2(t_i-t_{i-1})
Va r ( ∫ s t H z d W ( z )) ≈ Va r ( i = 1 ∑ N H t i ( W t i − W t i − 1 )) = i = 1 ∑ N Va r ( H t i ( W t i − W t i − 1 )) = i = 1 ∑ N H t i 2 Va r ( W t i − W t i − 1 ) = i = 1 ∑ N H t i 2 ( t i − t i − 1 )
lim m a x Δ t i → 0 ∑ i = 1 N H t i 2 ( t i − t i − 1 ) = ∫ s t H z 2 d z \lim_{max \Delta t_i\to0}\sum_{i=1}^NH_{t_i}^2(t_i-t_{i-1})=\int_s^tH_z^2dz
ma x Δ t i → 0 lim i = 1 ∑ N H t i 2 ( t i − t i − 1 ) = ∫ s t H z 2 d z
由于 d θ ˉ t = d ∫ 0 t θ z d z = θ t \mathrm d\bar\theta_t=\mathrm d\int_0^t\theta_z\mathrm dz=\theta_t d θ ˉ t = d ∫ 0 t θ z d z = θ t
x ( t ) e θ ˉ t − x ( s ) e θ ˉ s = μ ( e θ ˉ t − e θ ˉ s ) + ∫ s t σ z e θ ˉ z d w ( z ) x(t)\mathrm e^{\bar\theta_t}-x(s)\mathrm e^{\bar\theta_s}=\mu(\mathrm e^{\bar\theta_t}-\mathrm e^{\bar\theta_s})+\int_s^t\sigma_z\mathrm e^{\bar\theta_z}\mathrm{dw}(z)
x ( t ) e θ ˉ t − x ( s ) e θ ˉ s = μ ( e θ ˉ t − e θ ˉ s ) + ∫ s t σ z e θ ˉ z dw ( z )
两边同时除以 e θ ˉ t \mathrm e^{\bar\theta_t} e θ ˉ t
x ( t ) = μ + ( x ( s ) − μ ) e − θ ˉ s : t + ∫ s t σ z e − θ ˉ z : t d w z x(t)=\mu+(x(s)-\mu)\mathrm e^{-\bar\theta_{s:t}}+\int_s^t\sigma_z\mathrm e^{-\bar\theta_{z:t}}\mathrm {dw}_z
x ( t ) = μ + ( x ( s ) − μ ) e − θ ˉ s : t + ∫ s t σ z e − θ ˉ z : t dw z
∫ s t σ z 2 e − 2 θ ˉ z : t d z = σ t 2 2 θ t e 0 − σ s 2 2 θ s e − 2 θ ˉ s : t = λ 2 ( 1 − e − 2 θ ˉ s : t ) \int_s^t\sigma_z^2\mathrm e^{-2\bar\theta_{z:t}}\mathrm dz=\frac{\sigma_t^2}{2\theta_t}e^0-\frac{\sigma^2_s}{2\theta_s}\mathrm e^{-2\bar\theta_{s:t}}=\lambda^2(1-\mathrm e^{-2\bar\theta_{s:t}})
∫ s t σ z 2 e − 2 θ ˉ z : t d z = 2 θ t σ t 2 e 0 − 2 θ s σ s 2 e − 2 θ ˉ s : t = λ 2 ( 1 − e − 2 θ ˉ s : t )
证毕
当 t → ∞ t\to\infty t → ∞ m t m_t m t μ \mu μ v t v_t v t λ 2 \lambda^2 λ 2
反向过程
d x = [ θ t ( μ − x ) − σ t 2 ∇ x log p t ( x ) ] d t + σ t d w ^ \mathrm dx=[\theta_t(\mu-x)-\sigma^2_t\nabla_x\log p_t(x)]dt+\sigma_t\mathrm d\hat w
d x = [ θ t ( μ − x ) − σ t 2 ∇ x log p t ( x )] d t + σ t d w ^
每一步的ground-truth score:
∇ x log p t ( x ∣ x ( 0 ) ) = − x ( t ) − m t ( x ) v t \nabla_x\log p_t(x|x(0))=-\frac{x(t)-m_t(x)}{v_t}
∇ x log p t ( x ∣ x ( 0 )) = − v t x ( t ) − m t ( x )
重新参数化 x ( t ) = m t ( x ) + v t ϵ t , ϵ ∼ n ( 0 , I ) x(t)=m_t(x)+\sqrt{v_t}\epsilon_t,\epsilon\sim\mathcal n(0,I) x ( t ) = m t ( x ) + v t ϵ t , ϵ ∼ n ( 0 , I )
∇ x log p t ( x ∣ x ( 0 ) ) = − ϵ t v t \nabla_x\log p_t(x|x(0))=-\frac{\epsilon_t}{\sqrt v_t}
∇ x log p t ( x ∣ x ( 0 )) = − v t ϵ t
训练噪声估计网络 ϵ ~ ϕ ( x ( t ) , μ , t ) \tilde\epsilon_\phi(x(t),\mu,t) ϵ ~ ϕ ( x ( t ) , μ , t )
L γ ( ϕ ) : = ∑ i = 1 T γ i E [ ∥ ϵ ~ ϕ ( x ( t ) , μ , t ) − ϵ i ∥ ] L_\gamma(\phi):=\sum_{i=1}^{T}\gamma_i\mathbb E[\left\|\tilde\epsilon_\phi(x(t),\mu,t)-\epsilon_i\right\|]
L γ ( ϕ ) := i = 1 ∑ T γ i E [ ∥ ϵ ~ ϕ ( x ( t ) , μ , t ) − ϵ i ∥ ]
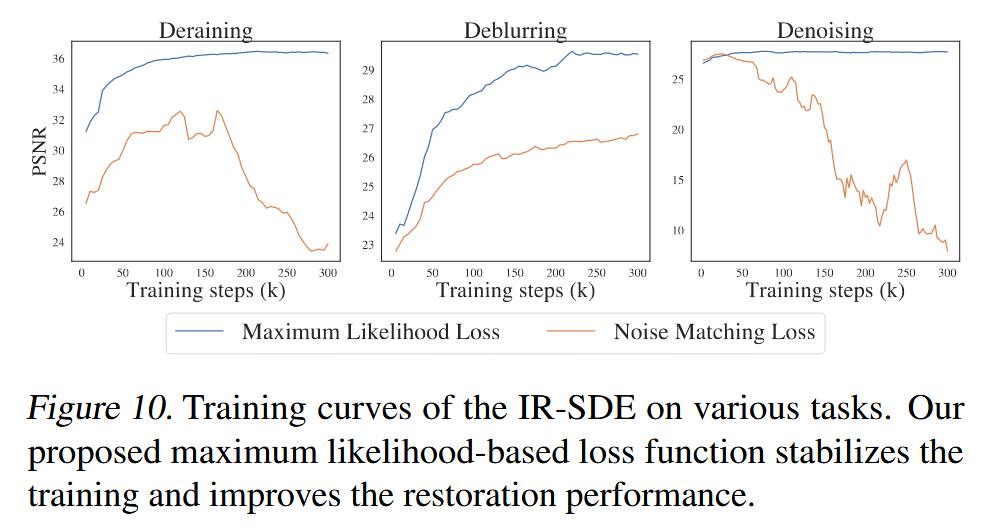
上式虽然比较简单,但是往往应用到复杂退化场景时会不稳定。原因:试图学习给定时间的瞬时噪声。
解决方法: 提出最大似然目标尝试寻找给定 x 0 x_0 x 0 x 1 : T x_{1:T} x 1 : T
最大似然目标:
p ( x 1 : T ∣ x 0 ) = p ( x T ∣ x 0 ) ∏ i = 2 T p ( x i − 1 ∣ x i , x 0 ) p(x_{1:T}|x_0)=p(x_T|x_0)\prod_{i=2}^Tp(x_{i-1}|x_i,x_0)
p ( x 1 : T ∣ x 0 ) = p ( x T ∣ x 0 ) i = 2 ∏ T p ( x i − 1 ∣ x i , x 0 )
于是最佳反向状态为最小化负的对数似然:
x i − 1 ∗ = a r g m i n x i − 1 [ − log p ( x i − 1 ∣ x i , x 0 ) ] x_{i-1}^*=\underset{x_{i-1}}{\mathrm{arg\ min}}[-\log p(x_{i-1}|x_i,x_0)]
x i − 1 ∗ = x i − 1 arg min [ − log p ( x i − 1 ∣ x i , x 0 )]
令 θ i ′ : = ∫ i − 1 i θ t d t \theta'_i:=\int_{i-1}^i\theta_t\mathrm dt θ i ′ := ∫ i − 1 i θ t d t
x i − 1 ∗ = 1 − e − 2 θ ˉ i − 1 1 − e − 2 θ ˉ i e − θ i ′ ( x i − μ ) + 1 − e − 2 θ i ′ 1 − e θ ˉ i ( x 0 − μ ) + μ x_{i-1}^*=\frac{1-\mathrm e^{-2\bar\theta_{i-1}}}{1-\mathrm e^{-2\bar\theta_i}}\mathrm e^{-\theta'_i}(x_i-\mu)\\
+\frac{1-\mathrm e^{-2\theta_i'}}{1-\mathrm e^{\bar\theta_i}}(x_0-\mu)+\mu
x i − 1 ∗ = 1 − e − 2 θ ˉ i 1 − e − 2 θ ˉ i − 1 e − θ i ′ ( x i − μ ) + 1 − e θ ˉ i 1 − e − 2 θ i ′ ( x 0 − μ ) + μ
证明:
根据贝叶斯规则
− log p ( x i − 1 ∣ x i , x 0 ) = − log p ( x i ∣ x i − 1 , x 0 ) p ( x i − 1 ∣ x 0 ) p ( x i ∣ x 0 ) ∝ − log p ( x i ∣ x i − 1 , x 0 ) − log p ( x i − 1 ∣ x 0 ) -\log p(x_{i-1}|x_i,x_0)=-\log\frac{p(x_i|x_{i-1},x_0)p(x_{i-1}|x_0)}{p(x_i|x_0)}\\
\propto -\log p(x_i|x_{i-1},x_0)-\log p(x_{i-1}|x_0)
− log p ( x i − 1 ∣ x i , x 0 ) = − log p ( x i ∣ x 0 ) p ( x i ∣ x i − 1 , x 0 ) p ( x i − 1 ∣ x 0 ) ∝ − log p ( x i ∣ x i − 1 , x 0 ) − log p ( x i − 1 ∣ x 0 )
令负的对数似然的梯度为0:
证毕,二阶导数为正,因此 x i − 1 ∗ x_{i-1}^* x i − 1 ∗
训练噪声估计网络 ϵ ~ ϕ ( x i , μ , i ) \tilde\epsilon_\phi(x_i,\mu,i) ϵ ~ ϕ ( x i , μ , i )
J γ ( ϕ ) : = ∑ i = 1 T γ i E [ ∥ x i − ( d x i ) ϵ ~ ϕ − x i − 1 ∗ ∥ ] J_\gamma(\phi):=\sum_{i=1}^T\gamma_i\mathbb E[\left\|x_i-(dx_i)_{\tilde\epsilon_\phi}-x_{i-1}^*\right\|]
J γ ( ϕ ) := i = 1 ∑ T γ i E [ x i − ( d x i ) ϵ ~ ϕ − x i − 1 ∗ ]
( d x i ) ϵ ~ ϕ (dx_i)_{\tilde\epsilon_\phi} ( d x i ) ϵ ~ ϕ ( 14 ) (14) ( 14 ) ϵ ~ ϕ \tilde\epsilon_\phi ϵ ~ ϕ
实验
Deraining
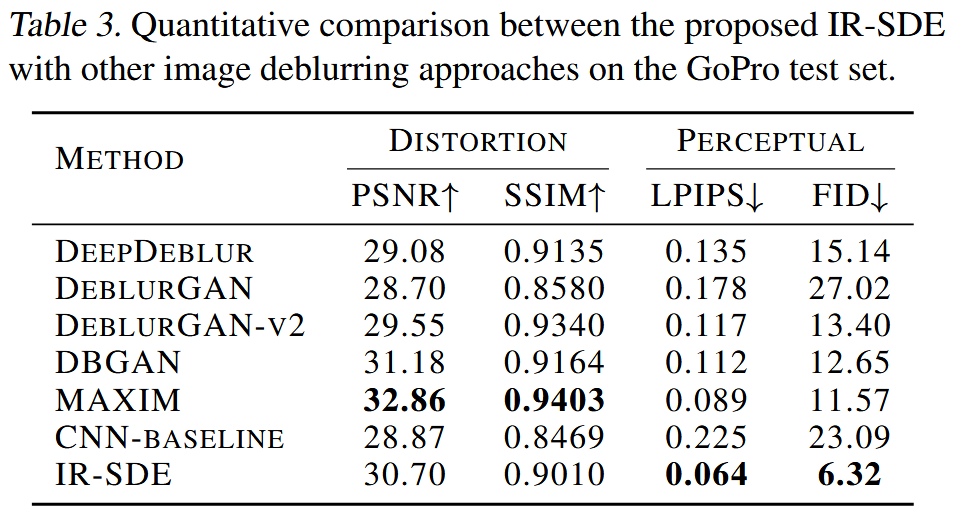
Debluring
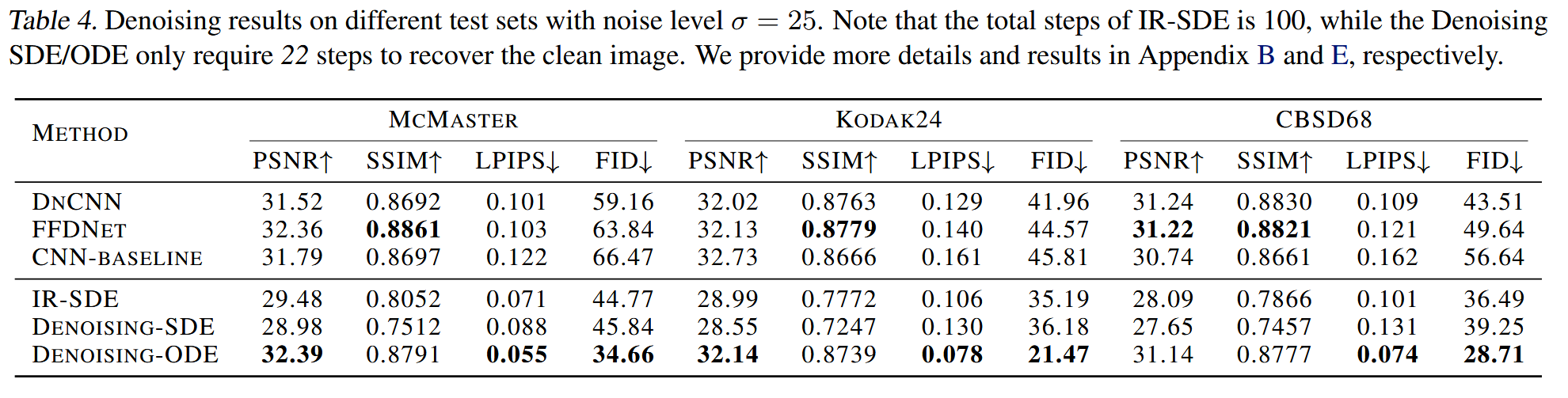
Gaussian Image Denoising
提出Denoising-SDE:将干净图像设为均值 μ = x 0 \mu=x_0 μ = x 0
提出Denoising-ODE:由于只有高斯噪声,因此可以直接使用ODE,没有额外的噪声直接去噪:
d x = [ θ t ( μ − x ) − σ t 2 ∇ x log p t ( x ) ] d t \mathrm dx=[\theta_t(\mu-x)-\sigma^2_t\nabla_x\log p_t(x)]dt
d x = [ θ t ( μ − x ) − σ t 2 ∇ x log p t ( x )] d t
p n o i s e ( x i ∣ x 0 ) = N ( m i ( x 0 ) , v i ) p_{noise}(x_i|x_0)=\mathcal N(m_i(x_0),v_i)
p n o i se ( x i ∣ x 0 ) = N ( m i ( x 0 ) , v i )
这里的 m i ( x 0 ) = x 0 , v i = λ 2 ( 1 − e − 2 θ ˉ i ) m_i(x_0)=x_0,v_i=\lambda^2(1-e^{-2\bar\theta_i}) m i ( x 0 ) = x 0 , v i = λ 2 ( 1 − e − 2 θ ˉ i )
x i − 1 ∗ = 1 − e − 2 θ ˉ i − 1 1 − e − 2 θ ˉ i e − θ i ′ ( x i − x 0 ) + x 0 x_{i-1}^*=\frac{1-\mathrm e^{-2\bar\theta_{i-1}}}{1-\mathrm e^{-2\bar\theta_i}}\mathrm e^{-\theta'_i}(x_i-x_0)+x_0
x i − 1 ∗ = 1 − e − 2 θ ˉ i 1 − e − 2 θ ˉ i − 1 e − θ i ′ ( x i − x 0 ) + x 0
x i = m i + v i ϵ t , ϵ ∼ N ( 0 , I ) x_i=m_i+\sqrt{v_i}\epsilon_t,\epsilon\sim\mathcal N(0,I)
x i = m i + v i ϵ t , ϵ ∼ N ( 0 , I )
将式 ( 26 ) (26) ( 26 ) ( 14 ) (14) ( 14 )
对应的ODE:
d x = − 1 2 σ t 2 e − 2 θ ˉ t ∇ x t log p t ( x ) d t dx=-\frac12\sigma_t^2\mathrm e^{-2\bar\theta_t}\nabla_{x_t}\log p_t(x)dt
d x = − 2 1 σ t 2 e − 2 θ ˉ t ∇ x t log p t ( x ) d t
一旦知道真实噪声水平 σ r e a l \sigma_{real} σ re a l t ∗ t^* t ∗ p n o i s e ( x i ∣ x 0 ) p_{noise}(x_i|x_0) p n o i se ( x i ∣ x 0 )
σ r e a l 2 = v t = λ 2 ( 1 − e − 2 θ ˉ t ) \sigma_{real}^2=v_t=\lambda^2(1-\mathrm e^{-2\bar\theta_t})
σ re a l 2 = v t = λ 2 ( 1 − e − 2 θ ˉ t )
于是:
t ∗ = a r g m i n t ∥ θ ˉ t − 1 2 Δ t log ( 1 − σ r e a l 2 λ 2 ) ∥ t^*=\underset{t}{arg\ min}\left\|\bar\theta_t-\frac1{2\Delta t}\log (1-\frac{\sigma_{real}^2}{\lambda^2 })\right\|
t ∗ = t a r g min θ ˉ t − 2Δ t 1 log ( 1 − λ 2 σ re a l 2 )
局限与未来方向
v t v_t v t 解决方案 :改进 θ \theta θ
采样步骤的优化,以减少计算成本
参考
[1] Z. Luo, F. K. Gustafsson, Z. Zhao, J. Sjölund, and T. B. Schön, “Image Restoration with Mean-Reverting Stochastic Differential Equations.” arXiv, May 31, 2023. Accessed: Nov. 13, 2023. [Online]. Available: http://arxiv.org/abs/2301.11699