Tackling the Generative Learning Trilemma with Denoising Diffusion GANs
背景
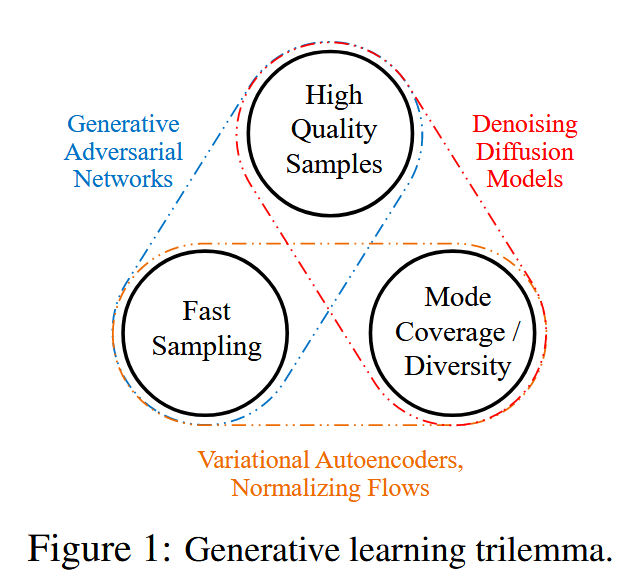
生成式学习三困境:高质量采样,多样性,快速采样。
传统扩散每一步的高斯假设只在去噪步长非常小的时候成立,因此反向过程需要很多步,而反向过程中步长较大(更少的去噪步数)时,需要使用非高斯多峰分布来建模去噪分布。
贡献
将扩散模型缓慢采样的原因归结为每一步去噪分布的高斯假设(p θ ( x t − 1 ∣ x t ) p_\theta(x_{t-1}|x_t) p θ ( x t − 1 ∣ x t )
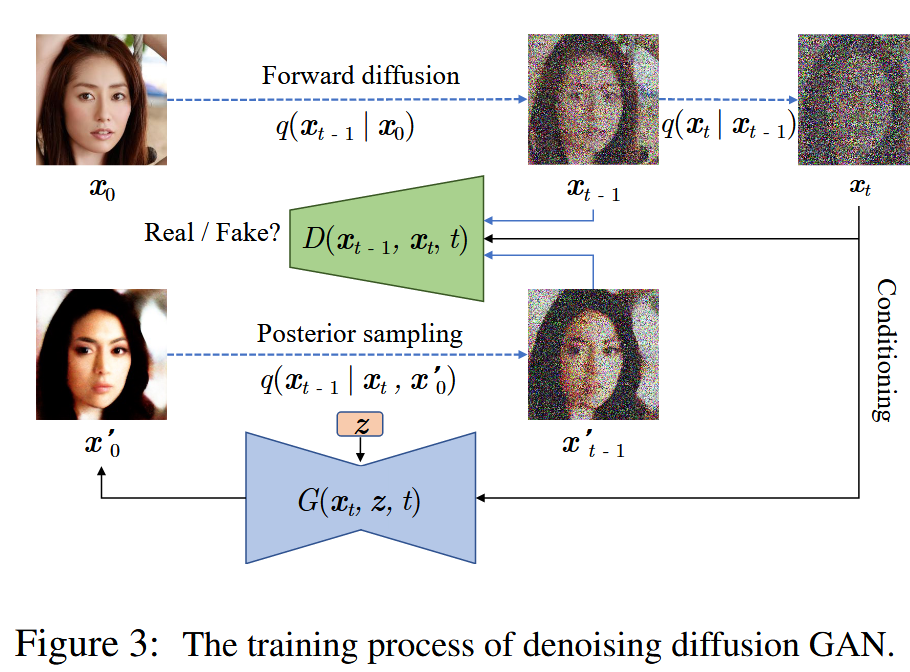
提出 Denoising Diffusion GANs,使用 conditional GANs参数化扩散模型的反向过程。
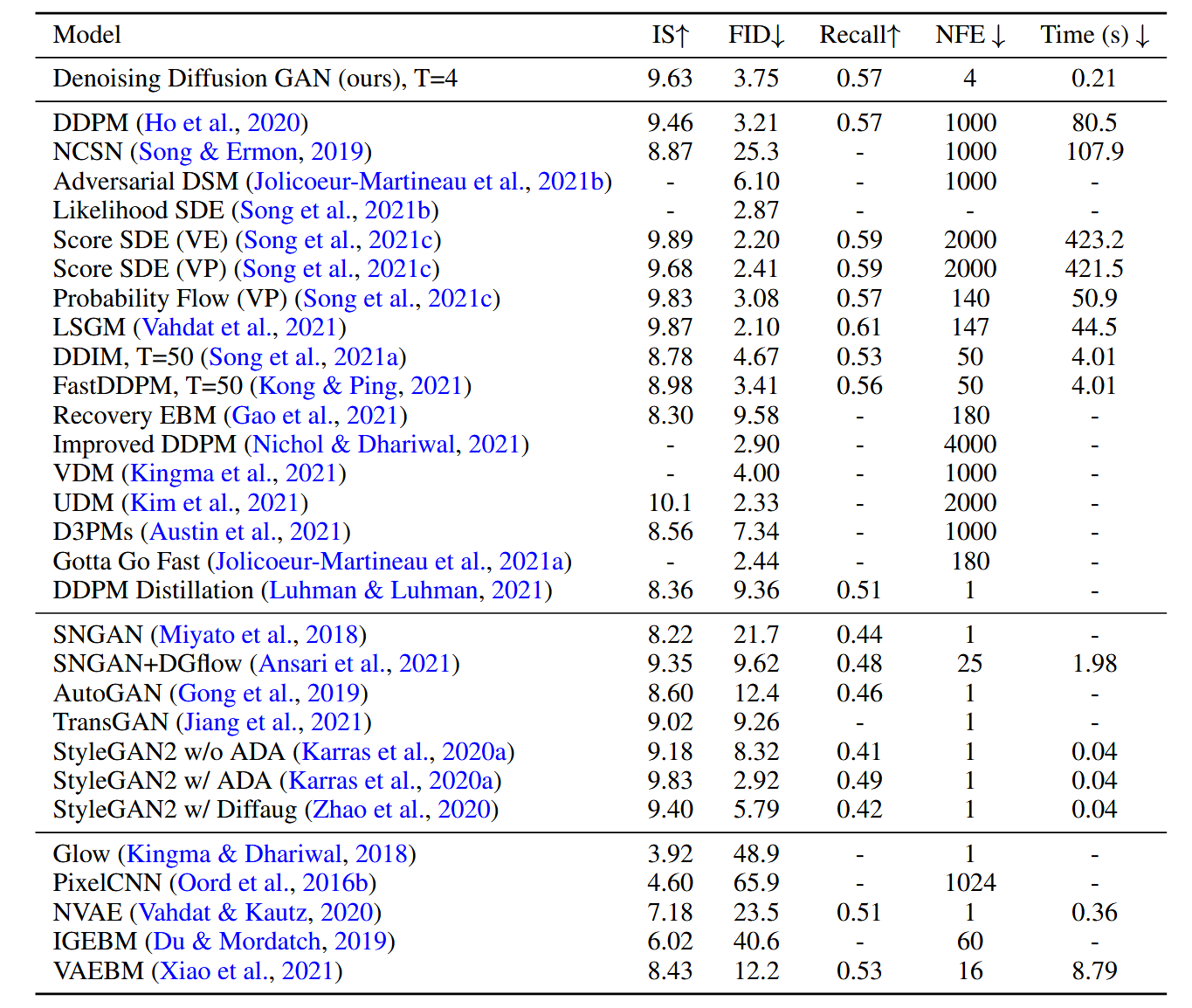
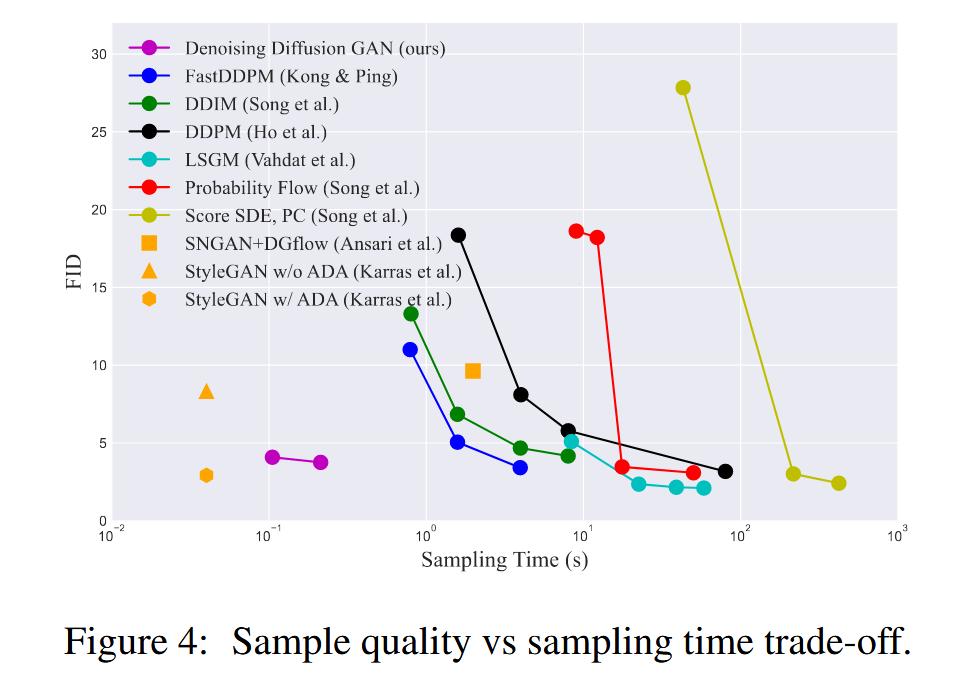
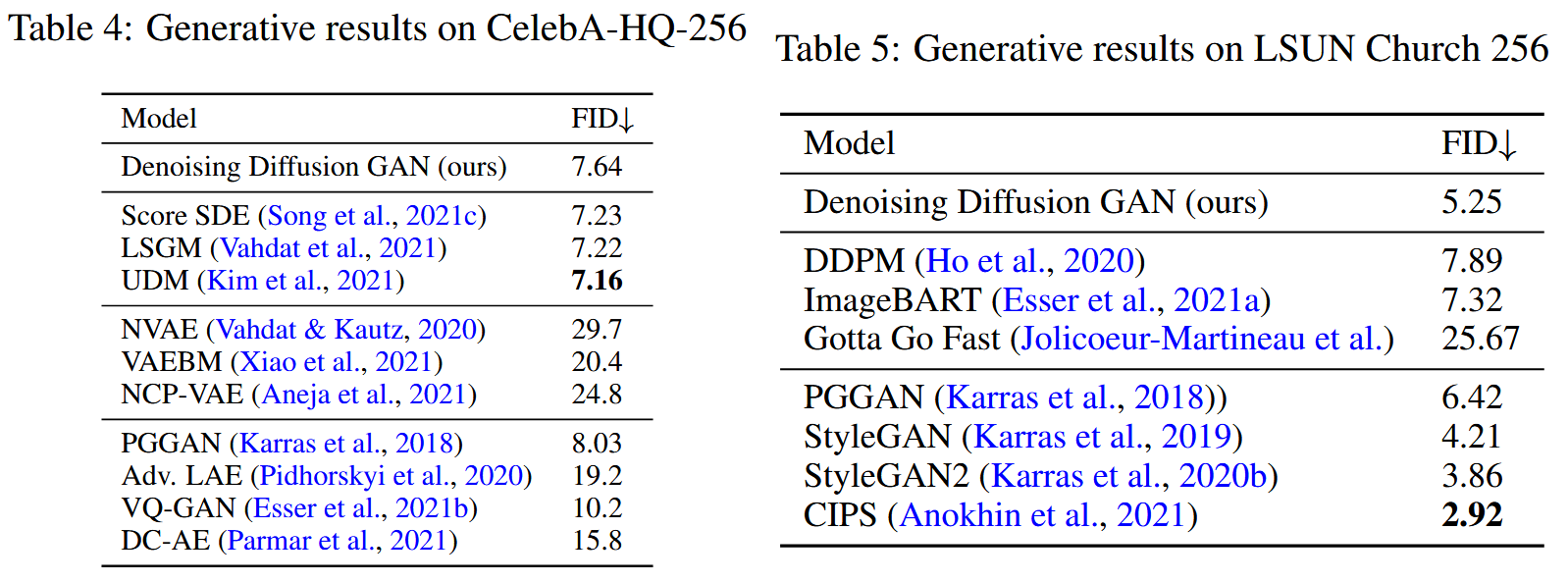
与现存的扩散模型相比,diffusion GAN实现了几个数量级的加速。
方法
Multimodel Denoising Distributions for Large Denoising Steps
高斯假设在何时正确?
当步长 β t \beta_t β t q ( x t − 1 ∣ x t ) ∝ q ( x t ∣ x t − 1 ) q ( x t − 1 ) q(x_{t-1}|x_t)\propto q(x_t|x_{t-1})q(x_{t-1}) q ( x t − 1 ∣ x t ) ∝ q ( x t ∣ x t − 1 ) q ( x t − 1 ) q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q ( x t ∣ x t − 1 ) q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q ( x t ∣ x t − 1 ) q ( x t − 1 ∣ x t ) q(x_{t-1}|x_t) q ( x t − 1 ∣ x t ) β t \beta_t β t
如果 q ( x 0 ) q(x_0) q ( x 0 ) q ( x t − 1 ∣ x t ) q(x_{t-1}|x_t) q ( x t − 1 ∣ x t ) q ( x 0 ) q(x_0) q ( x 0 ) q ( x t ) q(x_t) q ( x t )
当两个条件都不满足时(去噪步长很大,且数据分布不是高斯分布),此时无法保证去噪分布为高斯分布。
当去噪步长越大时,真实的去噪分布变得越复杂和多峰。
Modeling Denoising Distributions With Conditional GANs
目标 :减少反向过程中的去噪步数 T
方法 :使用 conditional GANs 近似真实的去噪分布 q ( x t − 1 ∣ x t ) q(x_{t-1}|x_t) q ( x t − 1 ∣ x t )
q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I ) (1) q(x_t|x_{t-1})=\mathcal N(x_t;\sqrt{1-\beta_t}x_{t-1},\beta_t I) \tag{1}
q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I ) ( 1 )
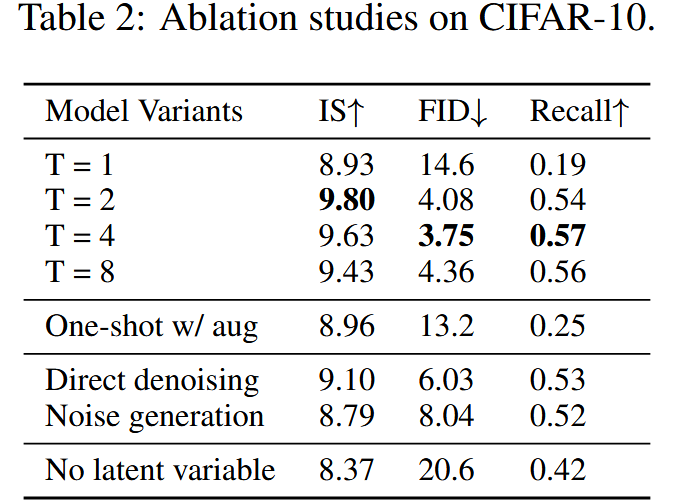
前向过程与普通扩散过程 ( 1 ) (1) ( 1 ) T ≤ 8 T\le 8 T ≤ 8 β t \beta_t β t
训练过程: 每一步去噪使用对抗损失最小化 D a d v D_{adv} D a d v p θ ( x t − 1 ∣ x t ) p_\theta(x_{t-1}|x_t) p θ ( x t − 1 ∣ x t ) q ( x t − 1 ∣ x t ) q(x_{t-1}|x_t) q ( x t − 1 ∣ x t )
m i n θ ∑ t ≥ 1 E q ( x t ) [ D a d v ( q ( x t − 1 ∣ x t ) ∥ p θ ( x t − 1 ∣ x t ) ) ] (2) \underset{\theta}{min} \sum_{t\ge 1}\mathbb E_{q(x_t)}[D_{adv}(q(x_{t-1}|x_t)\parallel p_\theta(x_{t-1}|x_t))]\tag{2}
θ min t ≥ 1 ∑ E q ( x t ) [ D a d v ( q ( x t − 1 ∣ x t ) ∥ p θ ( x t − 1 ∣ x t ))] ( 2 )
D a d v D_{adv} D a d v D ϕ ( x t − 1 , x t , t ) : R N × R N × N → [ 0 , 1 ] D_\phi(x_{t-1},x_t,t):\mathbb R^N\times \mathbb R^N\times \mathbb N\to[0,1] D ϕ ( x t − 1 , x t , t ) : R N × R N × N → [ 0 , 1 ] ϕ \phi ϕ x t − 1 x_{t-1} x t − 1 x t x_t x t x t − 1 x_{t-1} x t − 1 x t x_t x t
判别器训练 :
m i n ϕ ∑ t ≥ 1 E q ( x t ) [ E q ( x t − 1 ∣ x t ) [ − log ( D ϕ ( x t − 1 , x t , t ) ) ] + E p θ ( x t − 1 ∣ x t ) [ − log ( 1 − D ϕ ( x t − 1 , x t , t ) ) ] ] (3) \underset{\phi}{min}\sum_{t\ge1}\mathbb E_{q(x_t)}\big[\mathbb E_{q(x_{t-1}|x_t)}[-\log(D_\phi(x_{t-1},x_t,t))]+\mathbb E_{p_\theta(x_{t-1}|x_t)}[-\log(1-D_\phi(x_{t-1},x_t,t))]\big]\tag{3}
ϕ min t ≥ 1 ∑ E q ( x t ) [ E q ( x t − 1 ∣ x t ) [ − log ( D ϕ ( x t − 1 , x t , t ))] + E p θ ( x t − 1 ∣ x t ) [ − log ( 1 − D ϕ ( x t − 1 , x t , t ))] ] ( 3 )
由于第一项期望中的 q ( x t − 1 ∣ x t ) q(x_{t-1}|x_t) q ( x t − 1 ∣ x t )
q ( x t , x t − 1 ) = ∫ d x 0 q ( x 0 ) q ( x t − 1 , x t ∣ x 0 ) = ∫ d x 0 q ( x 0 ) q ( x t − 1 ∣ x 0 ) q ( x t ∣ x t − 1 , x 0 ) = ∫ d x 0 q ( x 0 ) q ( x t − 1 ∣ x 0 ) q ( x t ∣ x t − 1 ) (4) q(x_t,x_{t-1})=\int \mathrm dx_0q(x_0)q(x_{t-1},x_t|x_0)\\
=\int\mathrm dx_0q(x_0)q(x_{t-1}|x_0)q(x_t|x_{t-1},x_0)\\
=\int\mathrm dx_0q(x_0)q(x_{t-1}|x_0)q(x_t|x_{t-1})\tag{4}
q ( x t , x t − 1 ) = ∫ d x 0 q ( x 0 ) q ( x t − 1 , x t ∣ x 0 ) = ∫ d x 0 q ( x 0 ) q ( x t − 1 ∣ x 0 ) q ( x t ∣ x t − 1 , x 0 ) = ∫ d x 0 q ( x 0 ) q ( x t − 1 ∣ x 0 ) q ( x t ∣ x t − 1 ) ( 4 )
于是 ( 3 ) (3) ( 3 )
E q ( x t ) q ( x t − 1 ∣ x t ) [ − log ( D ϕ ( x t − 1 , x t , t ) ) ] = E q ( x 0 ) q ( x t − 1 ∣ x 0 ) q ( x t ∣ x t − 1 ) [ − log ( D ϕ ( x t − 1 , x t , t ) ) ] (5) \mathbb E_{q(x_t)q(x_{t-1}|x_t)}[-\log(D_\phi(x_{t-1},x_t,t))]=\mathbb E_{q(x_0)q(x_{t-1}|x_0)q(x_t|x_{t-1})}[-\log(D_\phi(x_{t-1},x_t,t))]\tag{5}
E q ( x t ) q ( x t − 1 ∣ x t ) [ − log ( D ϕ ( x t − 1 , x t , t ))] = E q ( x 0 ) q ( x t − 1 ∣ x 0 ) q ( x t ∣ x t − 1 ) [ − log ( D ϕ ( x t − 1 , x t , t ))] ( 5 )
生成器训练 :
m a x θ ∑ t ≥ 1 E q ( x t ) E p θ ( x t − 1 ∣ x t ) [ log ( D ϕ ( x t − 1 , x t , t ) ) ] (6) \underset{\theta}{max}\sum_{t\ge1}\mathbb E_{q(x_t)}\mathbb E_{p_\theta(x_{t-1}|x_t)}[\log(D_\phi(x_{t-1},x_t,t))]\tag{6}
θ ma x t ≥ 1 ∑ E q ( x t ) E p θ ( x t − 1 ∣ x t ) [ log ( D ϕ ( x t − 1 , x t , t ))] ( 6 )
参数化隐式去噪模型 :
p θ ( x t − 1 ∣ x t ) : = ∫ p θ ( x 0 ∣ x t ) q ( x t − 1 ∣ x t , x 0 ) d x 0 = ∫ p ( z ) q ( x t − 1 ∣ x t , x 0 = G θ ( x t , z , t ) ) d z (7) p_\theta(x_{t-1}|x_t):=\int p_\theta(x_0|x_t)q(x_{t-1}|x_t,x_0)\mathrm dx_0\\
=\int p(z)q(x_{t-1}|x_t,x_0=G_\theta(x_t,z,t))\mathrm dz\tag{7}
p θ ( x t − 1 ∣ x t ) := ∫ p θ ( x 0 ∣ x t ) q ( x t − 1 ∣ x t , x 0 ) d x 0 = ∫ p ( z ) q ( x t − 1 ∣ x t , x 0 = G θ ( x t , z , t )) d z ( 7 )
这里 z ∼ p ( z ) : = N ( z ; 0 , I ) z\sim p(z):=\mathcal N(z;0,I) z ∼ p ( z ) := N ( z ; 0 , I ) p θ ( x 0 ∣ x t ) p_\theta(x_0|x_t) p θ ( x 0 ∣ x t ) G θ ( x t , z , t ) : R N × R L × R → R N G_\theta(x_t,z,t):\mathbb R^N\times \mathbb R^L\times\mathbb R\to \mathbb R^N G θ ( x t , z , t ) : R N × R L × R → R N x t x_t x t z z z x 0 x_0 x 0
DDPM中的 x 0 x_0 x 0 x t x_t x t x 0 x_0 x 0 x t x_t x t x t − 1 x_{t-1} x t − 1 x 0 x_0 x 0
相对于一步生成器的优势 :众所周知,GAN的训练不稳定,且容易模式崩溃,原因可能是直接一步从复杂分布生成样本较为困难,以及判别器只看到正确样本时的过拟合问题。但是本文中的模型将生成过程分解为一系列条件去噪扩散过程,由于 x t x_t x t
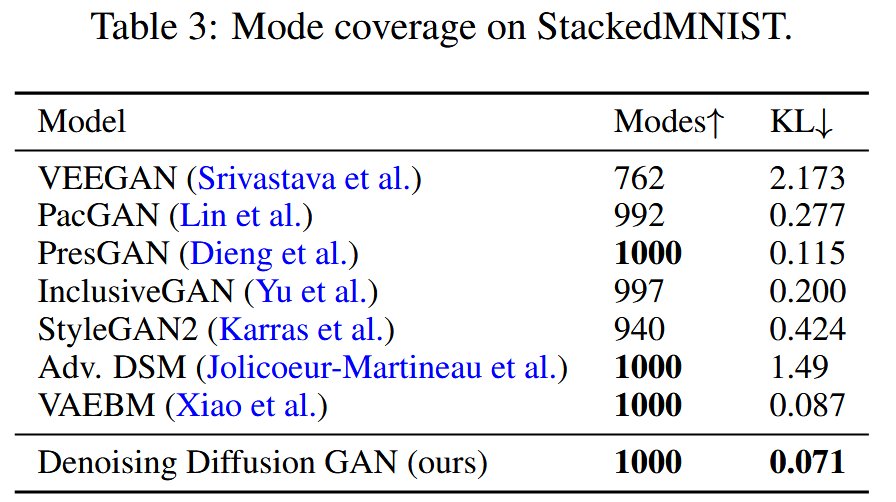
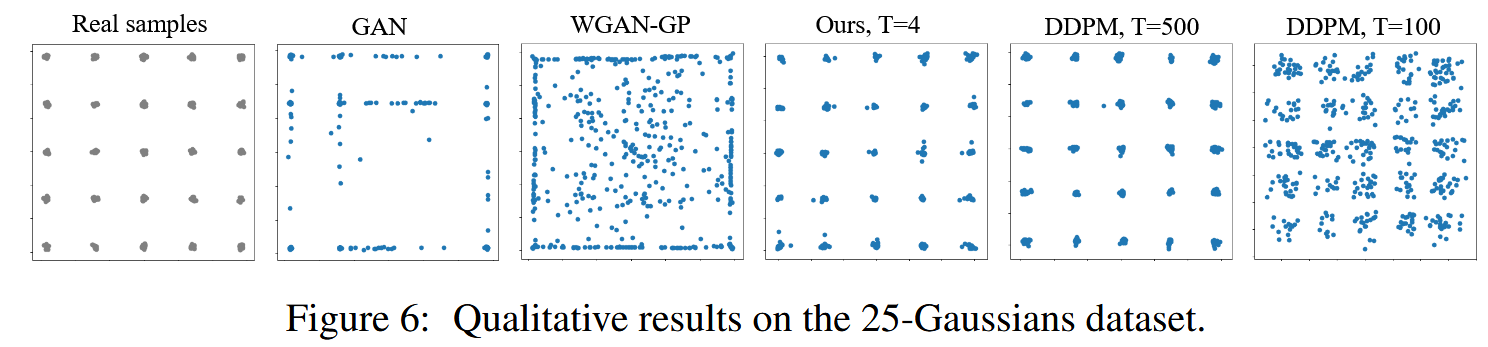
实验
参考
[1] Z. Xiao, K. Kreis, and A. Vahdat, “Tackling the Generative Learning Trilemma with Denoising Diffusion GANs.” arXiv, Apr. 04, 2022. doi: 10.48550/arXiv.2112.07804 .