CoSeR

CoSeR: Bridging Image and Language for Cognitive Super-Resolution
背景

人类专家在修复 LQ 图像时往往会首先对图像有一个理解,然后才会细化图像的细节;相反,基于卷积的方法会首先集中于局部内容以及像素级的处理,因此无法理解整幅图像的上下文,无法重建严重退化但语义上很重要的细节,以及可能会造成不正确的纹理。
基于以上的观察,作者认为需要给 SR 模型注入“认知”能力。
贡献
-
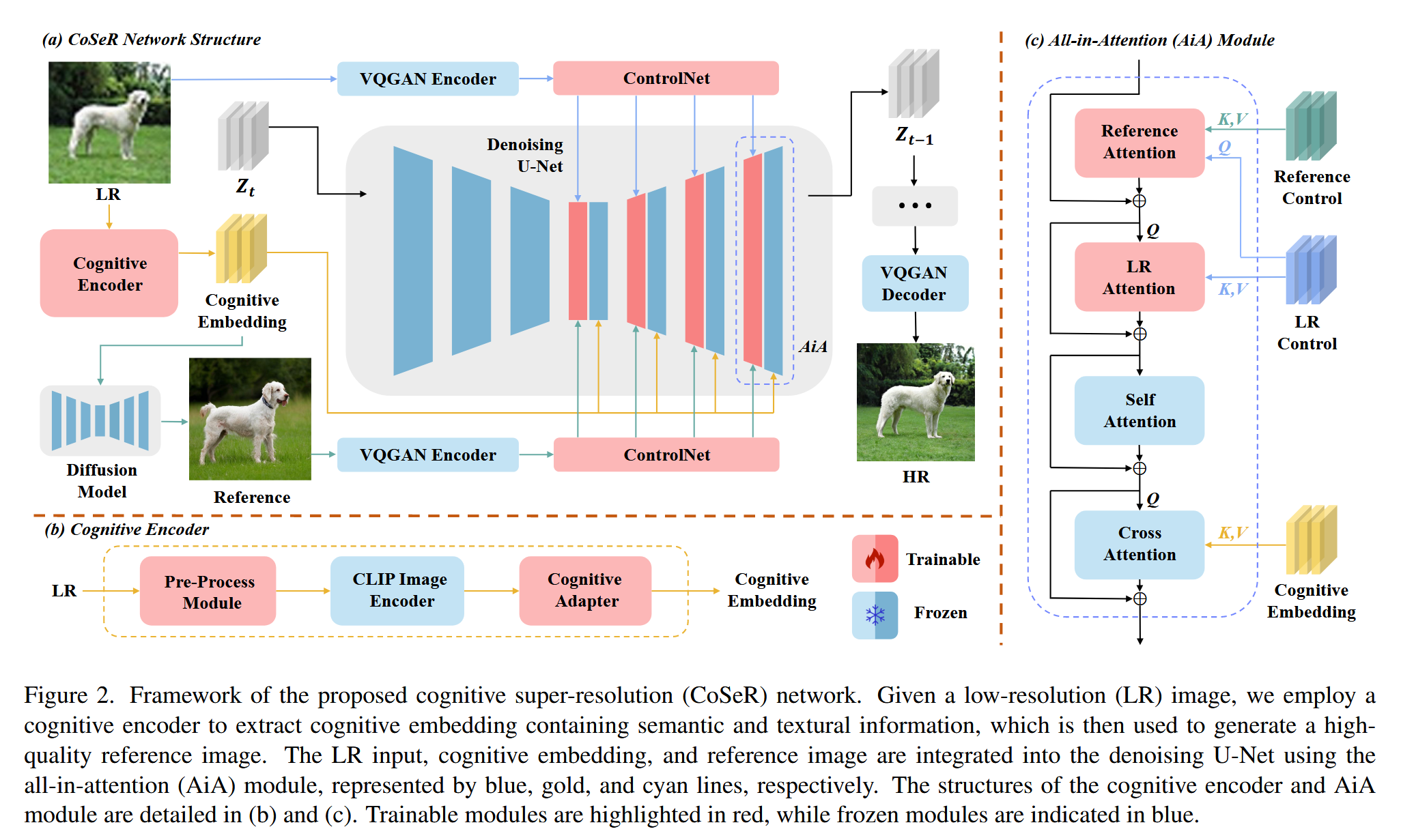
本文提出的 CoSeR 使得 SR 模型能够理解 LR 图像,通过结合图像外观与语言理解来生成cognitive embedding,不仅利用了 T2I 模型的先验信息,而且生成的高质量参考图像优化 SR 过程。
-
提出一个新的条件注入策略 “All-in-Attention”,将所有的条件信息合并到一个模组中
-
完成了语义上正确、照片级别的细节
CoSeR
https://summerwrain.github.io/2024/04/11/CoSeR/