MiniGPT4
MINIGPT-4: ENHANCING VISION-LANGUAGE UNDERSTANDING WITH ADVANCED LARGE LANGUAGE MODELS

动机:大多数GPT-4的多模态生成能力可以理解为两项基础能力图像理解以及语言生成的组合技能。以根据图像生成诗歌为例,大多数LLM已经有了很好的语言生成能力,如果它们获得了图像理解能力,即使训练数据集中没有图像-诗歌数据对,它们也可以根据图像生成诗歌。
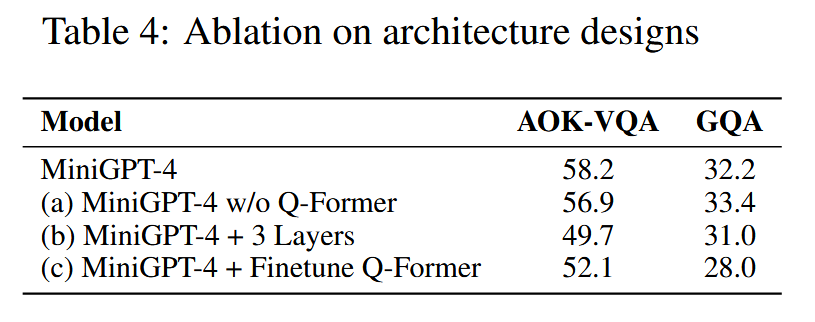
提出MiniGPT-4,使用一个投影层对齐冻结的视觉编码器(BLIP-2包括基于EVA-CLIP的ViT-G/14以及一个Q-Former)编码后的视觉特征和冻结的先进的LLM(Vicuna:基于LLaMA)
功能:实现了大多数GPT-4所拥有的多模态能力。如:详细的图像描述生成、根据手绘草图生成网站。此外还有一些其他能力:如根据图像写故事写诗、根据图片教用户如何做菜等。
初始预训练阶段在4*A100(80GB)上使用batch size为256训练20k steps,经过10个小时训练完成。使用LAION、Conceptual Captions和SBU组合的图像描述数据集对齐视觉特征和Vicuna语言模型。将投影层的输出作为LLM的“soft prompt”,提示它输出对应的GT texts。但是由于数据集中的语言风格和LLM生成风格不同,会导致产生不自然的输出,例如重复的单词或句子、支离破碎的句子或不相关的内容。
受GPT-3到GPT-3.5的启发,因此在二阶段通过精心设计的交流模板制作了3500对详细的图像描述数据集,进一步微调模型,恢复LLM的生成能力,改进模型的生成可靠性以及整体的可用性。具体来说,首先进行初始的图像-文本生成对齐,使用Vicuna的交流模板设计prompt:
###Human:
Describe this image in detail. Give as many details as possible. Say everything you see. ###Assistant:
为识别不完整的句子,会检查生成的句子是否超过80个token,如果没有则会添加一个额外的提示:###Human: Continue ###Assistant:提示模型延长生成过程,通过这两个步骤可以得到更全面的图像描述。然后从Conceptual Caption数据集中随机选取5000张图像生成语言描述,这些自动生成的图像描述会包含噪声或不连贯的描述,于是使用ChatGPT加入如下prompt来修复这些描述:

最终收集到3500个图像-文本对。在第二阶段使用模板
###Human:
###Assistant:
作为prompt训练,MiniGPT-4 现在能够产生更自然、更可靠的语言输出,整个阶段以batchsize为12训练400 steps,在单张A100上训练7分钟。