CLIP-LIT
Iterative Prompt Learning for Unsupervised Backlit Image Enhancement

CLIP不仅可以区分背光图像和正常光照图像,还可以感知不同亮度的异构区域,促进增强网络的优化。
问题:直接应用CLIP到增强任务难以找到准确的prompt
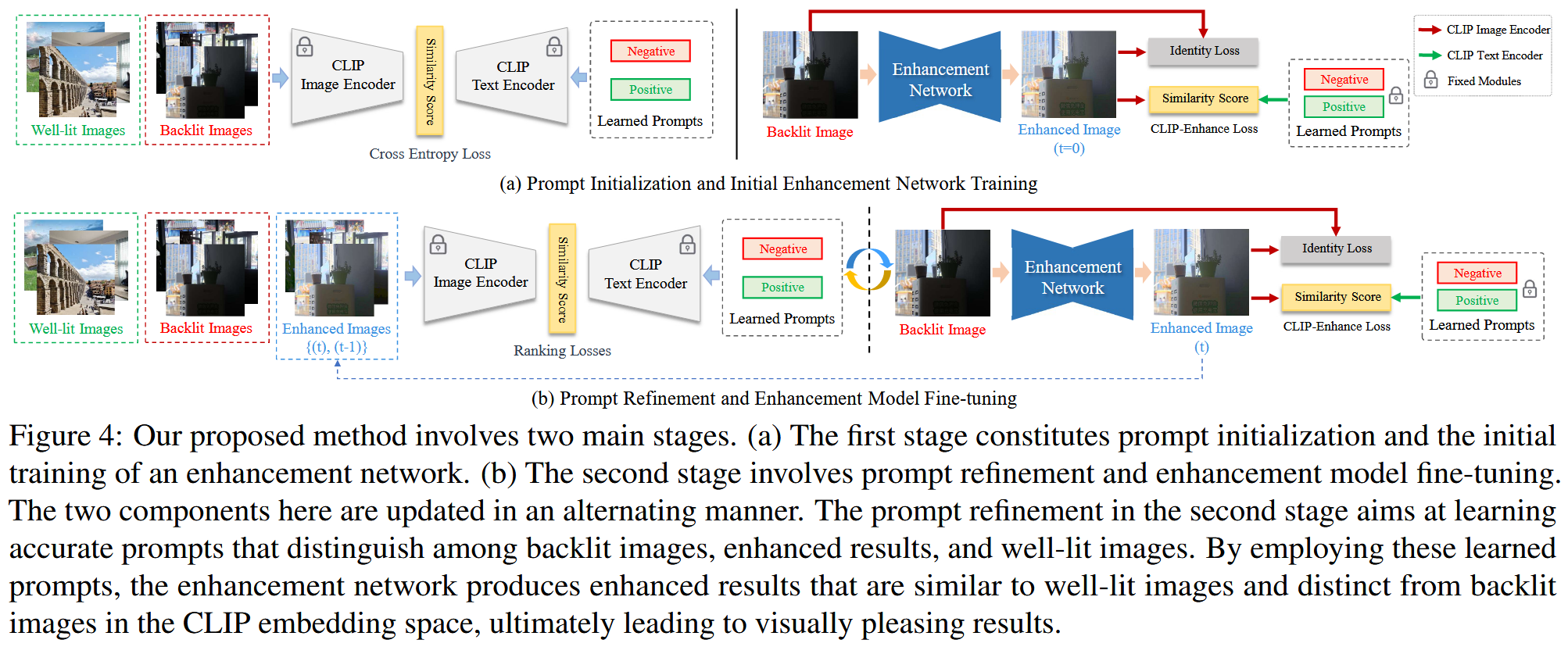
贡献:设计了一个学习框架,首先通过约束正/负prompt与背光/正常图像之间的相似度学习初始prompt,然后基于增强结果与初始prompt对之间的相似度训练增强网络。为了更进一步提高prompt的准确率,因此进一步的迭代微调prompt学习框架减小背光图像,增强结果,正常图像之间的gaps
Prompt Initialization:
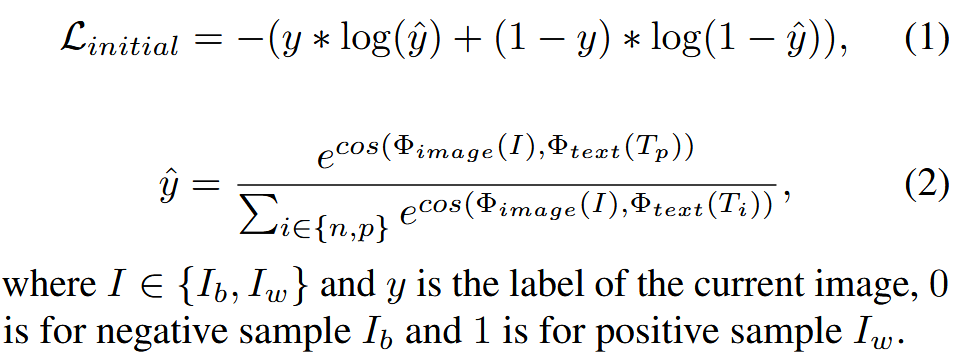
Training the Initial Enhancement Network:
使用一个简单的Unet增强背光图像,受到Retinex模型的启发,增强网络预测一个光照图 然后通过 生成最后的结果。

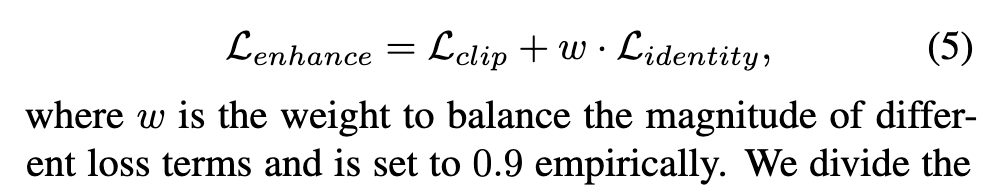
首先使用 identity loss 训练 self-reconstruction 使得增强结果和背光图像在像素空间上相近,然后,同时使用 indentity loss 和 CLIP-Enhance loss训练网络。在训练 self-reconstruction 期间, 。在训练增强网络期间, ,这是因为作者发现最后一层与图像的颜色更相关,而这需要调整。
Prompt Refinement and Enhancement Tuning
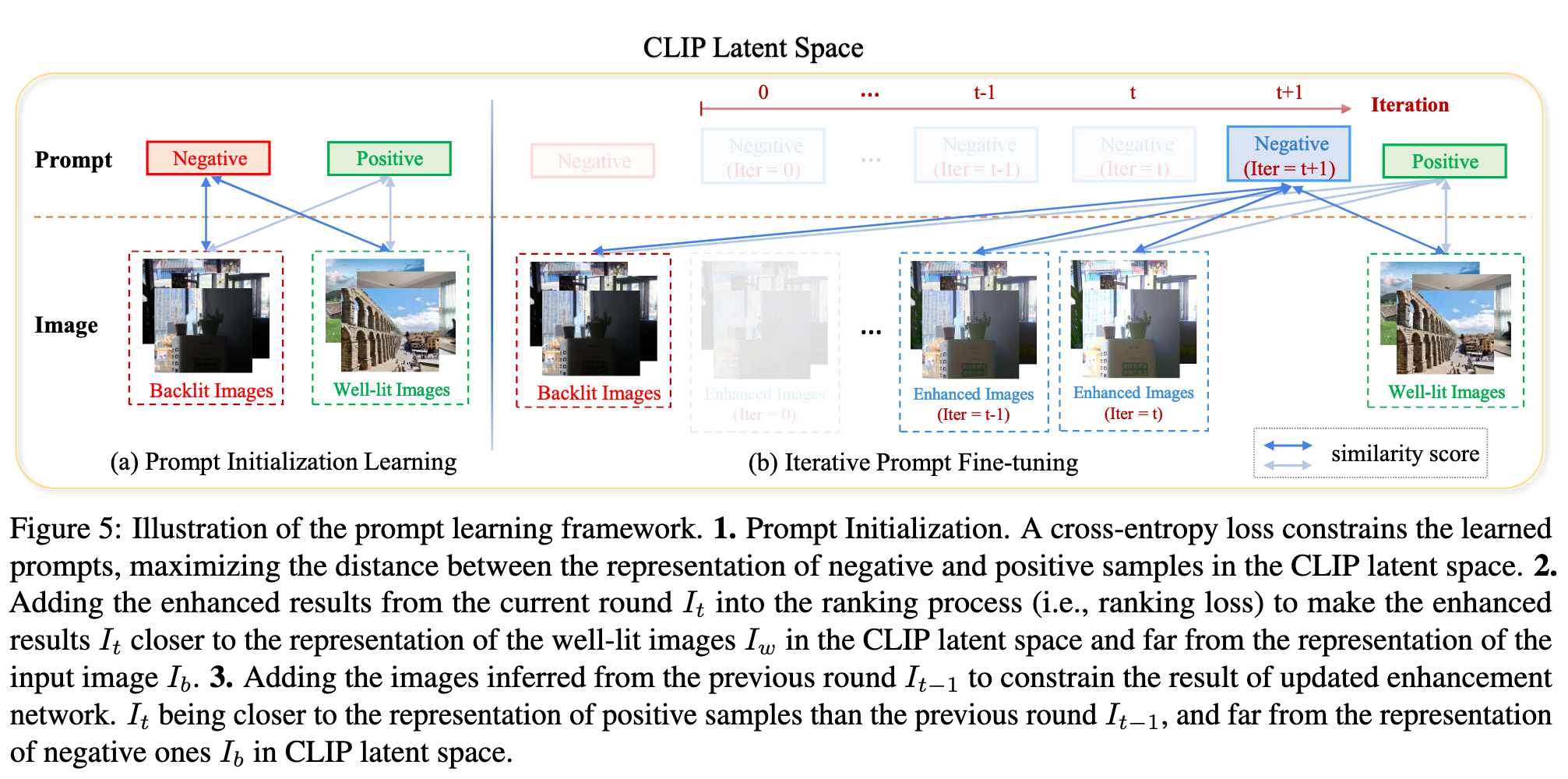
初始的prompts可能无法很好的捕捉到背光图像、增强图像和正常图像之间的差异

设置 尽可能地使得增强结果和正常图像的距离更大, 使得增强结果和正常结果更接近。
为了使得每次迭代性能都能提升,加入两组新的约束,使得新学到的prompts更集中于图像的光照和颜色分布,而不是高级内容。

增强网络的调整与前面保持一致。
讨论:
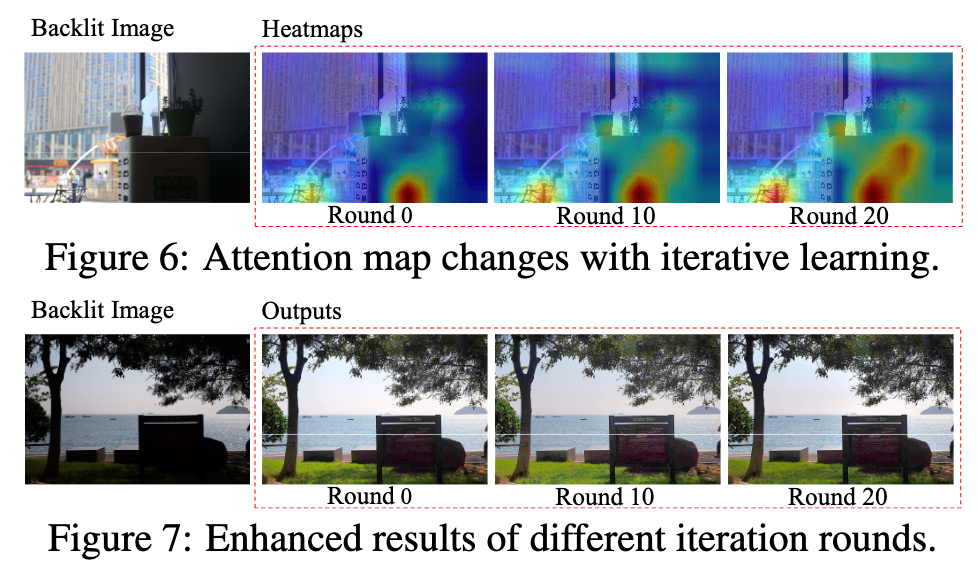
在迭代期间,学到的 negative prompt 与不理想的光照和颜色越来越相关;在中间轮,增强区域的颜色输出是过饱和的,在迭代次数足够多时,过饱和现象被矫正,同时黑暗区域相对于之前的输出接近于正常状态。
实验


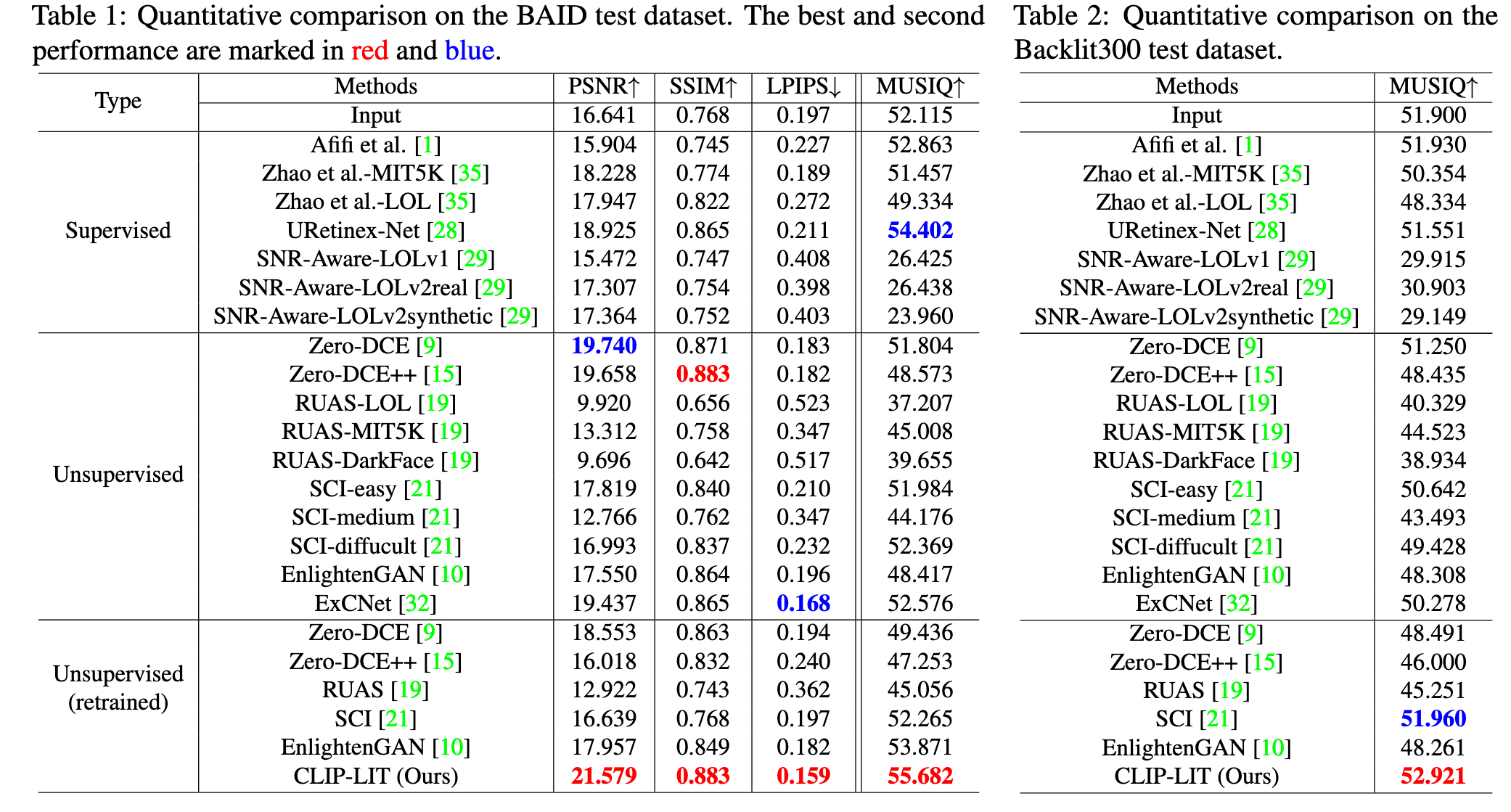

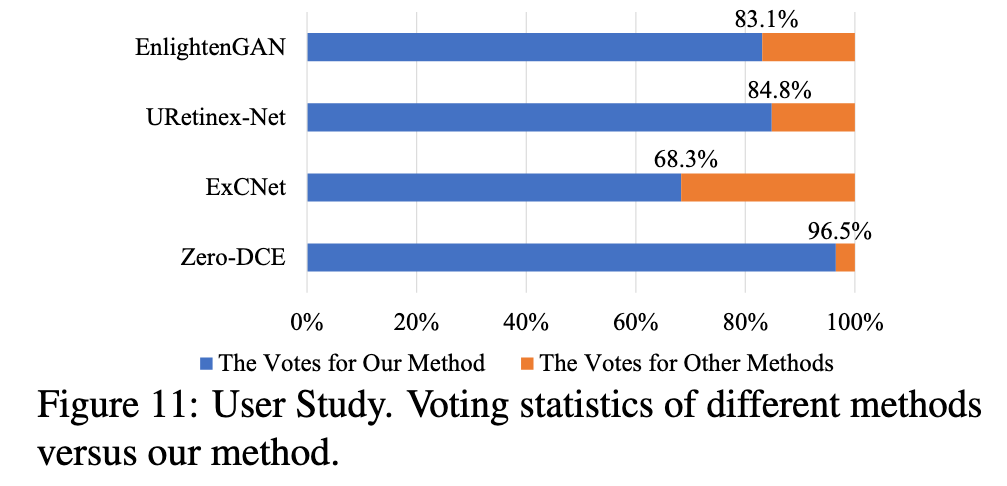


评论
学到的prompts应该可以进一步的使用,在本文中只使用prompt去算损失,感觉有点大材小用