DeCo
DeCo: Decoupling Token Compression from Semantic Abstraction in Multimodal Large Language Models

背景
Visual projector 可以融合视觉和语言模态并促进多模态之间的对齐。当前的研究利用中间的 projector 将视觉 patch 映射到 LLM 隐空间作为视觉 tokens,主要分为非压缩式(MiniGPT4、LLaVA)和压缩式(BLIP-2)
非压缩式:直接使用线性层映射,视觉 tokens 数不变,训练成本高
压缩式:压缩原始的视觉 tokens 为更少的 query tokens,(e.g.,Q-Former)将 visual patches 抽象为有限的语义概念,比如对象或描述,会导致“double abstraction”现象。
projector 参考预定义好的query 进行第一次视觉语义提取,LLM 基于文本指导进行第二次提取。
训练低效、累积性视觉语义损失
贡献
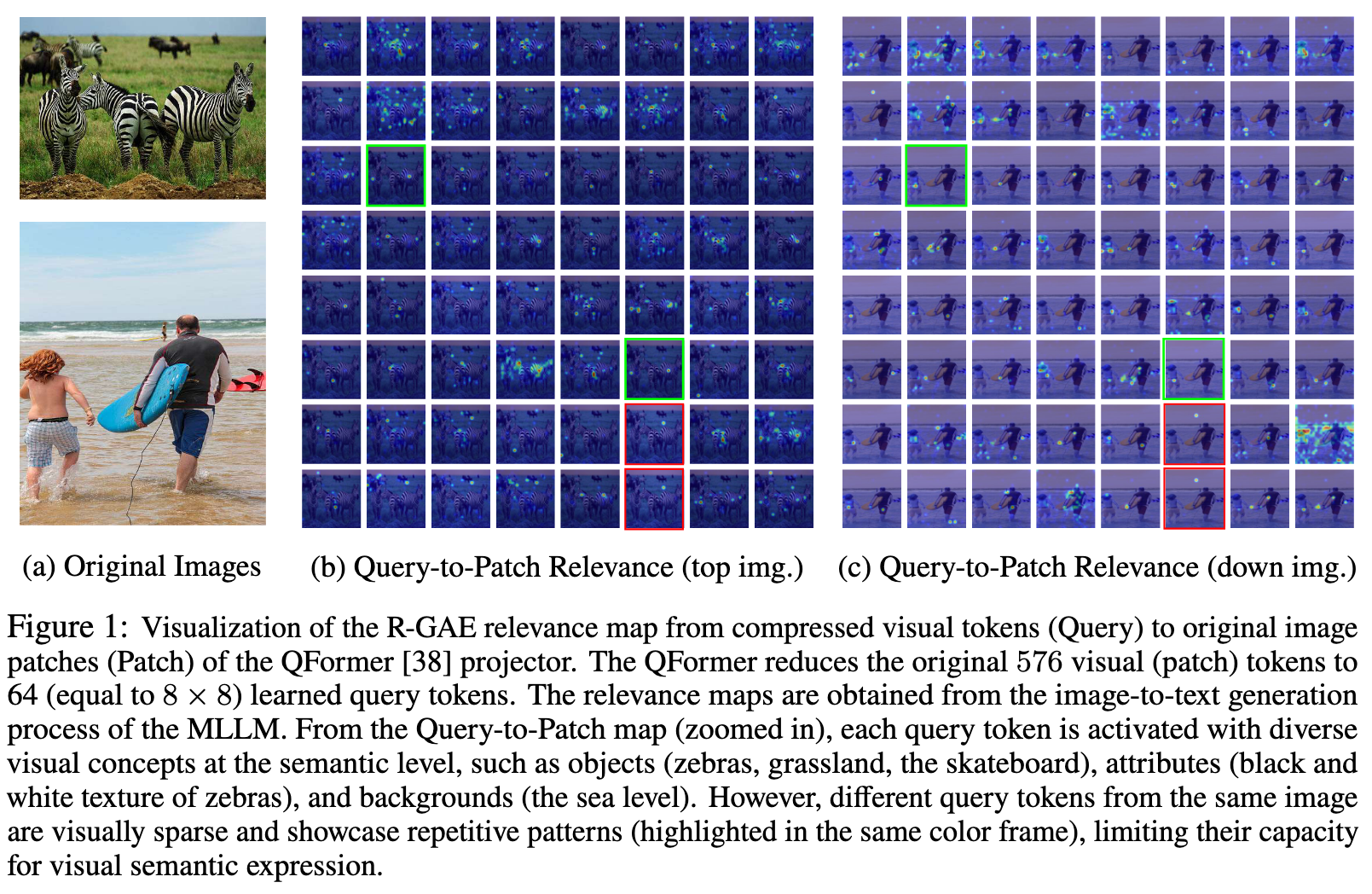
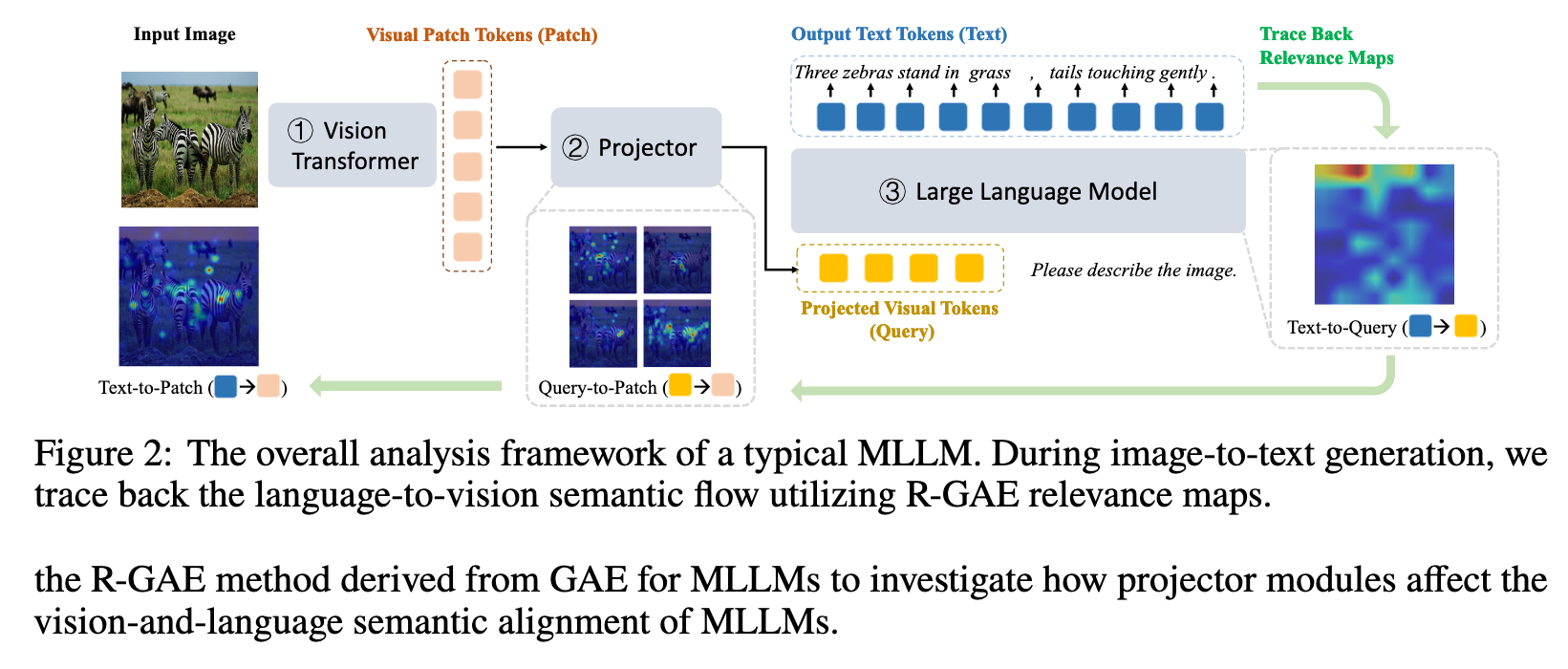
- 使用 R-GAE 分析生成的文本 tokens,原始视觉 tokens 以及中间的投影输出的相关性,将 Text-to-Patch 解耦为 Text-to-query 和 Query-to-Patch
- 提出 DeCo 在 patch 水平压缩视觉 token 的数量(2D Adaptive Pooling 下采样),然后使用线性层映射维度,允许 LLM 直接处理视觉语义信息
- 两个发现:1. 在语义水平使用 query tokens 压缩视觉 tokens 的数量会使得细粒度特征和空间信息的损失,固定数目的 query 只能表达有限的视觉信息;2. 非压缩式的线性层 projector 允许 LLM 观察 patch 水平的视觉特征,并关注准确的空间位置
分析
Query-Patch 图可以解释通过 query(压缩)tokens 学到的视觉模式,而 Text-Patch 和 Text-Query 之间的差异揭示了 projector 对视觉-语言语义对齐的影响
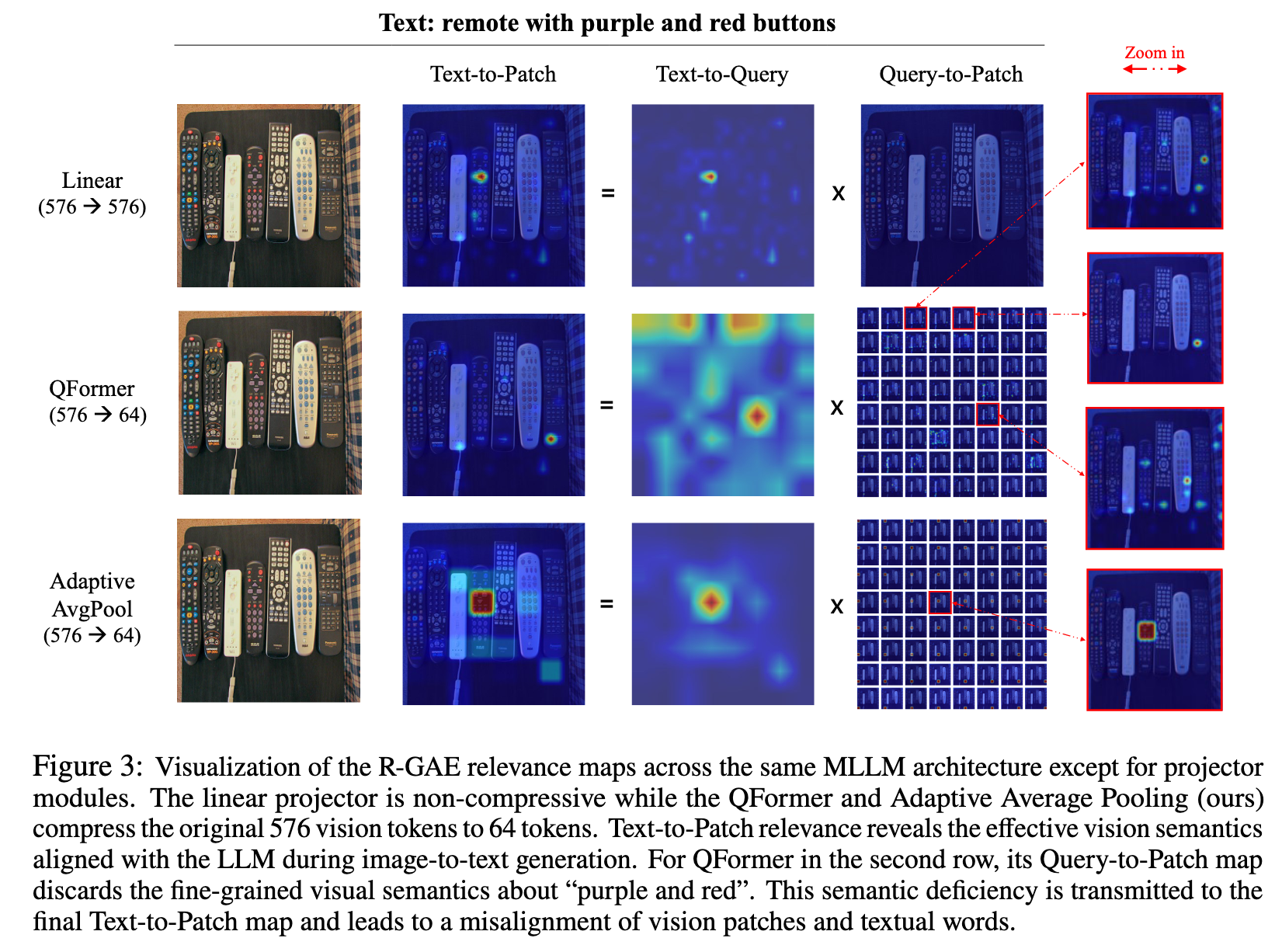
- LLM 可以直接从 patch 特征中很好的抽取视觉信息
- 压缩式的 projector 只能提取有限的视觉概念,视觉上重复+语义上稀疏
- MLLM 系统的低效是因为 double abstraction
DeCo: Decoupling Vision Token Compression
集中于在 patch 水平降低视觉 tokens 的数量
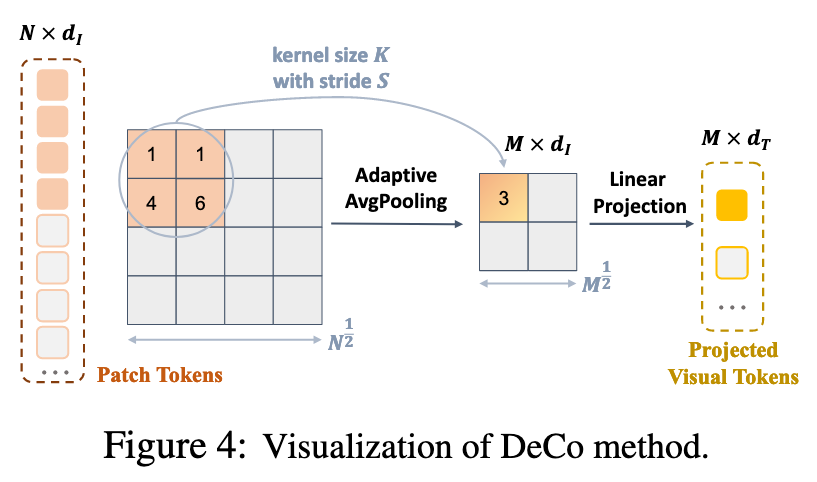
1D->2D->Adaptive AvgPooling->Linear layer
实质上,Adaptive AvgPooling合并了空间上相邻的有较高视觉冗余的 patch tokens,有效+高效
实验
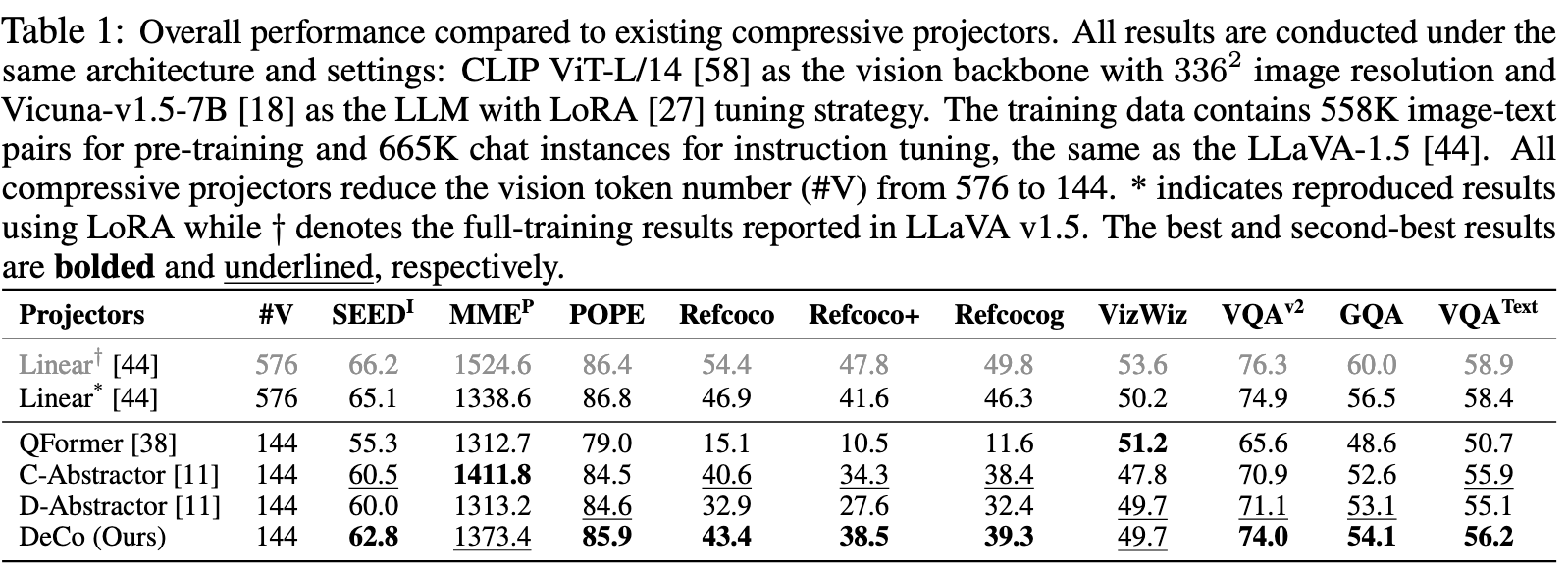
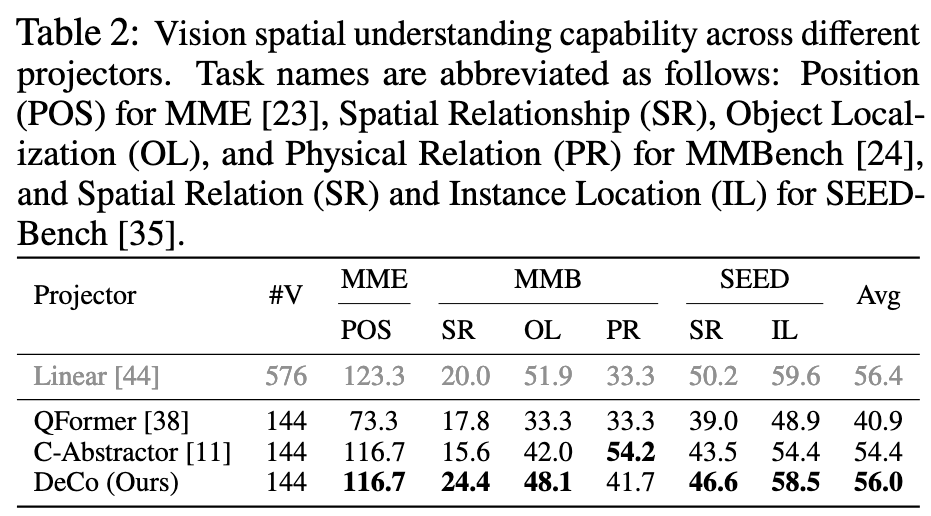
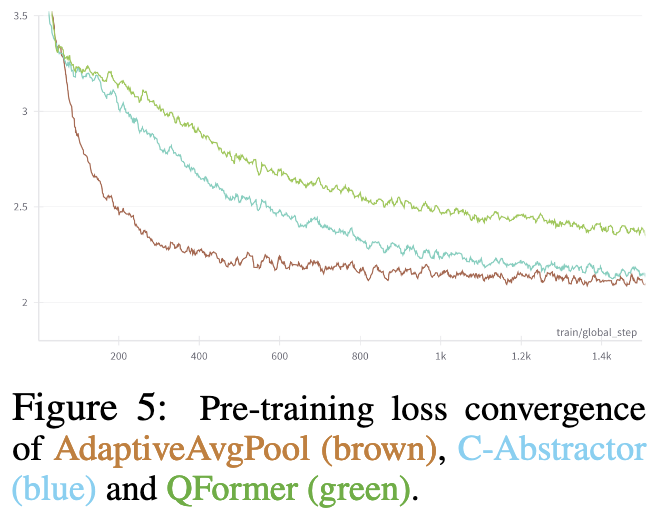
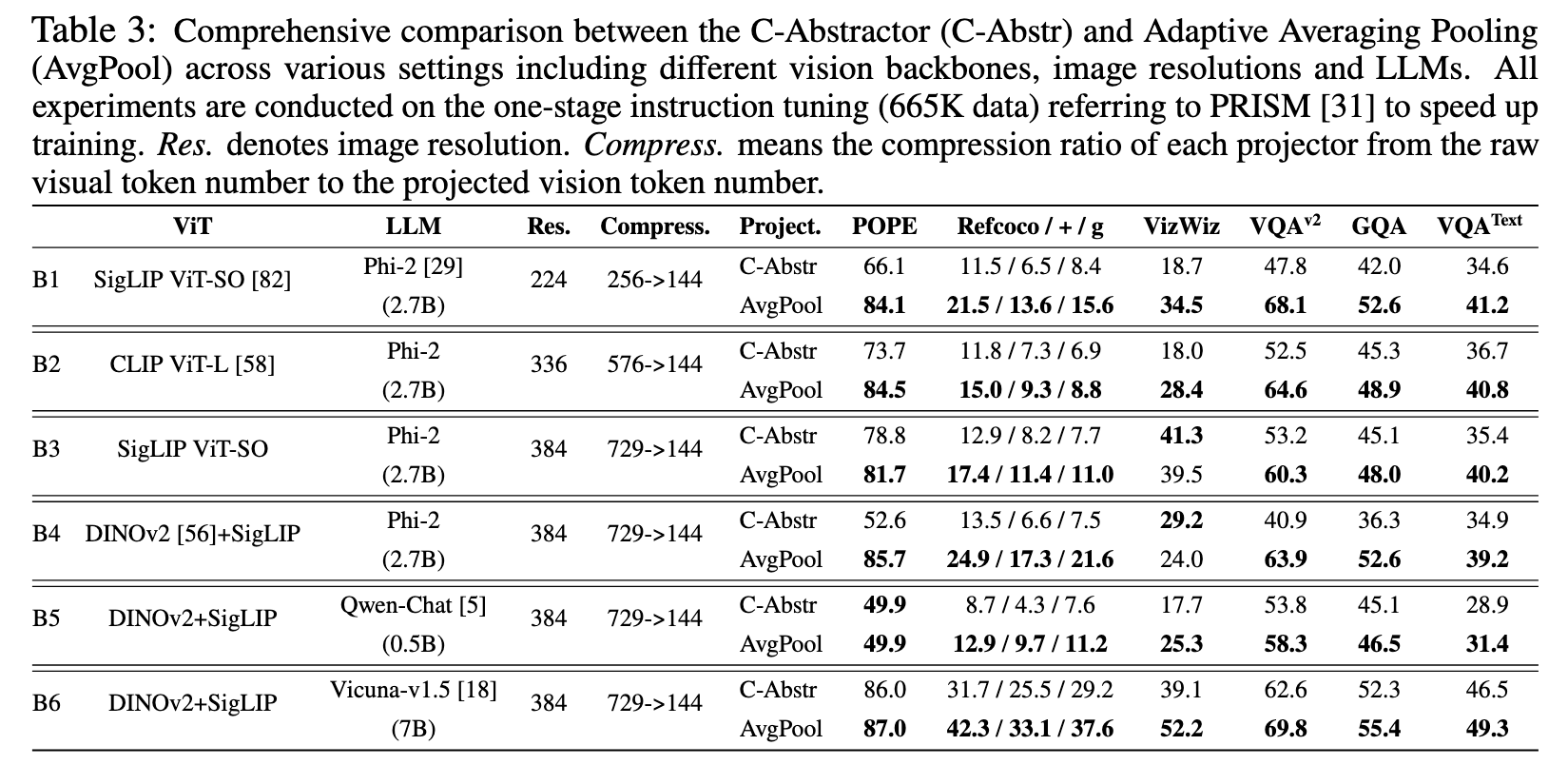
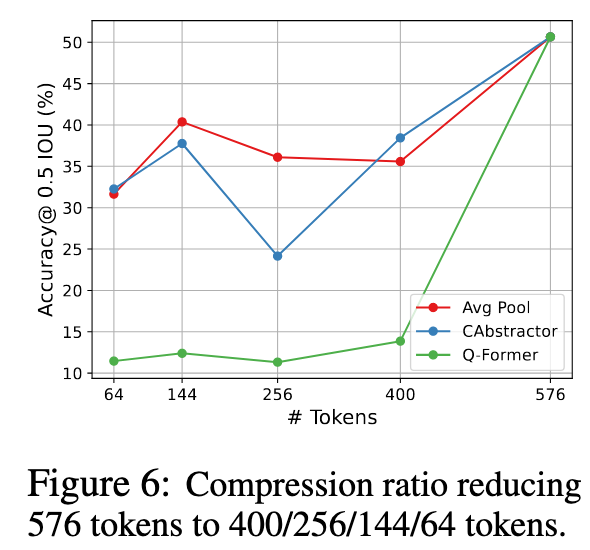
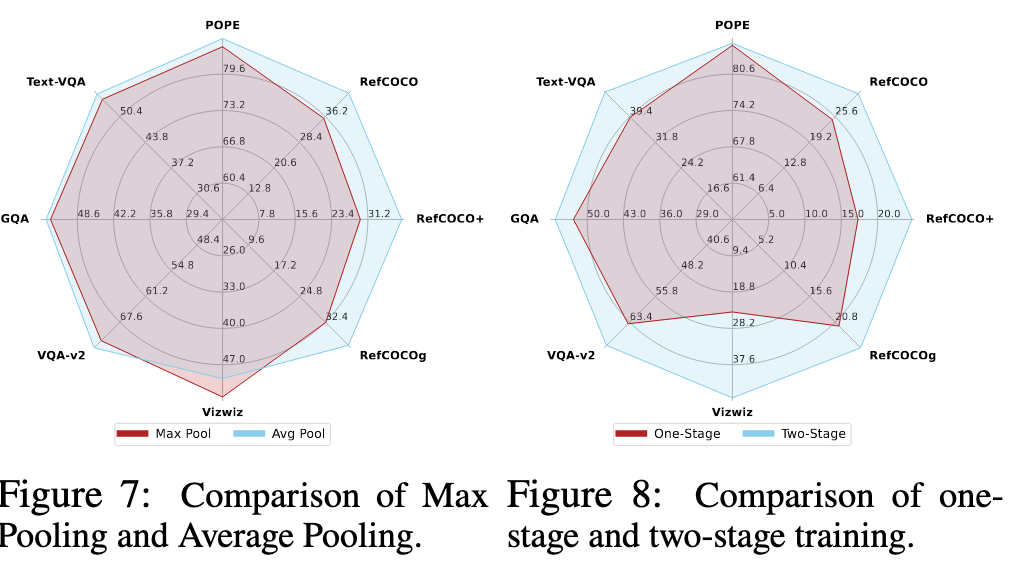
局限性
在较高压缩比下,也可能会造成视觉信息损失;在资源充足的情况下(足够多训练资源,训练数据),projector 结构改变的作用不明显;不局限于 AdaptiveAvgPool
DeCo
https://summerwrain.github.io/2024/09/01/DeCo/