ELITE
ELITE: Encoding Visual Concepts into Textual Embeddings for Customized Text-to-Image Generation
背景
customized 文本到图像的生成问题:由于用户可能会使用难以形容的、个人的一些概念去创造一些有想象力的样本(例:“柯基”)。通常需要从用户提供的少量图片集合去学习特定的概念,现存工作使用一种基于优化的方法来学习 customized 概念,但是会带来过多的计算和内存负担。

基于GAN和VAE的方法不能很好的匹配用户的描述,大文生图模型也难以表达特定的或用户定义的概念。
贡献
为快速准确的 customized 文本到图像生成提出基于学习的编码器ELITE,由全局-局部映射网络组成,直接将视觉概念编码为文本嵌入。在将学习到的概念编辑到一个新的场景中时有较好的灵活性,同时保留图像特有的细节。
全局映射网络将给定图像的层级特征投射到文本的 word embedding 空间中的多个“新”的单词中(例:一个主词表示可编辑的概念,以及其他辅助词来排除不相关的干扰);局部映射网络将编码后的 patch 特征注入到交叉注意力层以提供遗漏的细节。
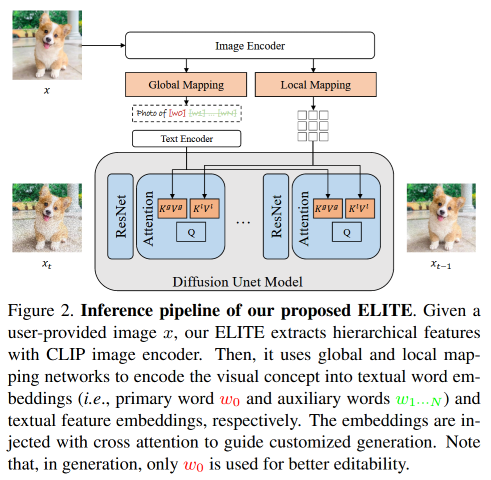
方法
预备
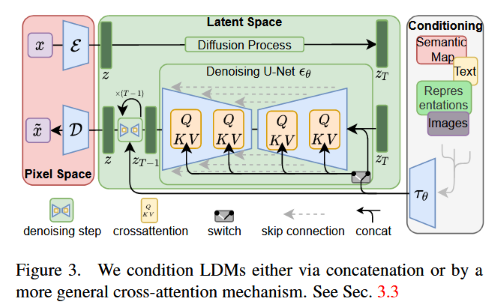
使用 Stable diffusion 作为文生图模型:首先训练一个autoencoder,encoder 将一张图像映射到低维空间,同时decoder 将隐编码还原为一张图像;然后在隐空间上训练条件扩散模型 ,基于条件 生成隐编码。使用均方误差来训练:
表示CLIP text-encoder。推理时,高斯噪声 逐渐去噪为 ,然后最终的图像通过decoder得到
交叉注意力 为了在生成过程中利用文本信息
, 为隐图像特征, 为文本特征, 为key和query的输出维度,隐图像特征通过注意力块更新。
全局映射网络
使用CLIP图像编码器 作为特征提取器,全局映射网络 特征投影到CLIP文本编码器的文本词嵌入 :
, 为单词数, 为词向量的维度,对特征使用全局平均池化来获得词嵌入。由于一张图像会有主体和其他不相关元素,编码为单个单词会损失主体的可编辑性,于是分别学习主词和辅助词:从CLIP最深层特征学到主要概念(主体),从其他层学到的辅助词描述其他不相关元素。从CLIP图像编码器中选择 层,每一层 独立的学习一个单词
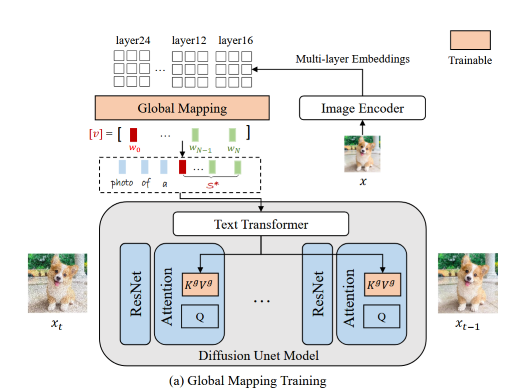
训练目标:
训练时随机从CLIP ImageNet templates采样一个文本作为文本输入,key 和 value 分别通过 微调。
局部映射网络
局部映射网络 将多层CLIP特征编码到文本特征空间中(文本编码器的输出空间)。
是对象的mask,用来回避背景中不需要的细节, 保持空间结构, 为特征的size。 的每个像素主要集中于给定图像的每个patch的局部细节,然后将得到的文本嵌入注入到交叉注意力层 ,与全局部分融合以改进局部细节:
为了强调目标区域,将得到的注意力图 通过 重新加权。
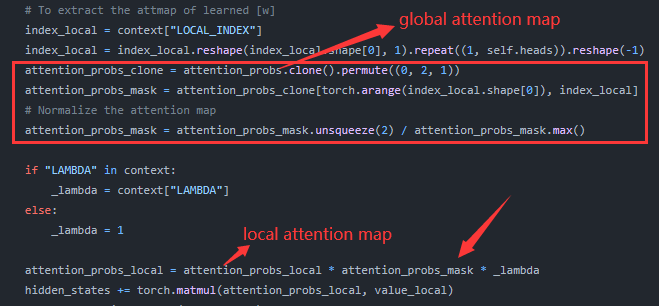
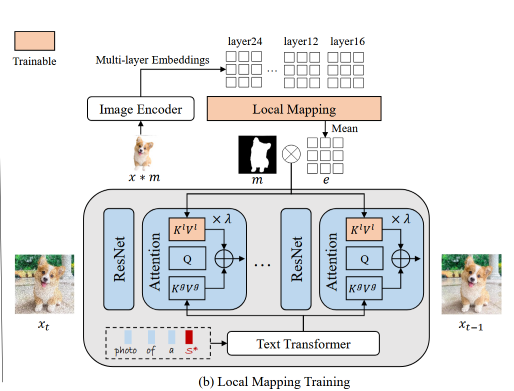
训练目标:
实验
使用OpenImage的测试集进行训练,主体mask通过预训练的分割模型得到。映射网络使用3层MLP,选择{24,4,8,12,16}层的CLIP特征,采样器使用LMS采样器。


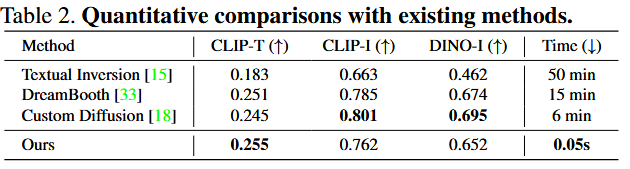
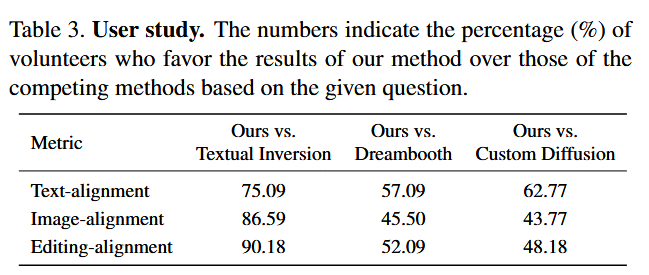

局限
不能处理涉及文本字符的图片:

参考
[1] Y. Wei, Y. Zhang, Z. Ji, J. Bai, L. Zhang, and W. Zuo, “ELITE: Encoding Visual Concepts into Textual Embeddings for Customized Text-to-Image Generation.” arXiv, Aug. 18, 2023. Accessed: Nov. 20, 2023. [Online]. Available: http://arxiv.org/abs/2302.13848
[2] R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-Resolution Image Synthesis with Latent Diffusion Models,” in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA: IEEE, Jun. 2022, pp. 10674–10685. doi: 10.1109/CVPR52688.2022.01042.